# Simulation and Monte Carlo Methods {#sec-simulation}
::: {.callout-note appearance="simple"}
## Learning Objectives
- Estimate expected values and full distributions via Monte Carlo sampling
- Build a discrete-event simulator for an M/M/1 queue from scratch
- Apply variance reduction techniques to improve estimator efficiency
- Use a Gaussian process surrogate to optimize expensive simulation models
:::
## Beyond Closed-Form Analysis
Chapters 8 and 9 handled uncertainty analytically — converting stochastic programs to
extensive-form LPs and robust programs to deterministic equivalents. Both approaches
require the recourse function $Q(x, \xi)$ to have tractable algebraic structure.
Many real systems do not. A hospital emergency department schedules staff against
uncertain patient arrivals, triage times, and treatment pathways. A logistics network
routes shipments through congested lanes with stochastic transit times and equipment
failures. A semiconductor fab manages machines whose failure modes interact in ways
that no closed-form model captures.
**Simulation** evaluates these systems by running many stochastic replications and
averaging the results. It is the practitioner's instrument for measuring what cannot
be derived. This chapter develops the core methods: Monte Carlo integration,
discrete-event simulation, variance reduction, and surrogate-based optimization.
```{=html}
<figure style="margin: 2rem 0;">
<svg viewBox="0 0 720 200" xmlns="http://www.w3.org/2000/svg" style="width:100%;max-width:720px;font-family:'DM Sans',system-ui,sans-serif;">
<defs>
<marker id="arr" markerWidth="8" markerHeight="6" refX="7" refY="3" orient="auto">
<polygon points="0 0,8 3,0 6" fill="#6b7280"/>
</marker>
<marker id="arr-hl" markerWidth="8" markerHeight="6" refX="7" refY="3" orient="auto">
<polygon points="0 0,8 3,0 6" fill="#1d4ed8"/>
</marker>
</defs>
<!-- row labels -->
<text x="10" y="58" font-size="10" fill="#9ca3af" letter-spacing=".06em">TRACTABLE</text>
<text x="10" y="148" font-size="10" fill="#9ca3af" letter-spacing=".06em">INTRACTABLE</text>
<line x1="110" y1="10" x2="110" y2="190" stroke="#e5e7eb" stroke-width="1"/>
<!-- tractable row -->
<rect x="126" y="30" width="130" height="44" rx="6" fill="#eff6ff" stroke="#bfdbfe" stroke-width="1"/>
<text x="191" y="52" text-anchor="middle" font-size="12" font-weight="500" fill="#1e40af">Analytical</text>
<text x="191" y="66" text-anchor="middle" font-size="10" fill="#3b82f6">LP, DP, closed-form</text>
<rect x="286" y="30" width="130" height="44" rx="6" fill="#f0fdf4" stroke="#bbf7d0" stroke-width="1"/>
<text x="351" y="52" text-anchor="middle" font-size="12" font-weight="500" fill="#166534">Stochastic prog.</text>
<text x="351" y="66" text-anchor="middle" font-size="10" fill="#16a34a">Scenarios, SAA</text>
<rect x="446" y="30" width="130" height="44" rx="6" fill="#fefce8" stroke="#fef08a" stroke-width="1"/>
<text x="511" y="52" text-anchor="middle" font-size="12" font-weight="500" fill="#854d0e">Robust optim.</text>
<text x="511" y="66" text-anchor="middle" font-size="10" fill="#ca8a04">Worst-case sets</text>
<!-- arrow down -->
<line x1="511" y1="74" x2="511" y2="110" stroke="#d1d5db" stroke-width="1" marker-end="url(#arr)"/>
<text x="520" y="96" font-size="9" fill="#9ca3af" font-style="italic">fails when Q(x,ξ)</text>
<text x="520" y="107" font-size="9" fill="#9ca3af" font-style="italic">has no algebra</text>
<!-- intractable row — highlighted -->
<rect x="126" y="118" width="130" height="50" rx="6" fill="#eff6ff" stroke="#bfdbfe" stroke-width="1"/>
<text x="191" y="140" text-anchor="middle" font-size="12" font-weight="500" fill="#1e40af">DES</text>
<text x="191" y="155" text-anchor="middle" font-size="10" fill="#3b82f6">Queues, dynamics</text>
<rect x="286" y="118" width="130" height="50" rx="6" fill="#eff6ff" stroke="#bfdbfe" stroke-width="1"/>
<text x="351" y="140" text-anchor="middle" font-size="12" font-weight="500" fill="#1e40af">Monte Carlo</text>
<text x="351" y="155" text-anchor="middle" font-size="10" fill="#3b82f6">Integration, risk</text>
<rect x="446" y="118" width="190" height="50" rx="6" fill="#fdf4ff" stroke="#e9d5ff" stroke-width="1.5"/>
<text x="541" y="138" text-anchor="middle" font-size="12" font-weight="600" fill="#7e22ce">Surrogate + BO</text>
<text x="541" y="153" text-anchor="middle" font-size="10" fill="#9333ea">GP + Bayesian optim.</text>
<text x="541" y="165" text-anchor="middle" font-size="9" fill="#a855f7" font-style="italic">← this chapter</text>
<!-- horizontal connectors -->
<line x1="256" y1="143" x2="286" y2="143" stroke="#6b7280" stroke-width="1" marker-end="url(#arr)"/>
<line x1="416" y1="143" x2="446" y2="143" stroke="#6b7280" stroke-width="1" marker-end="url(#arr)"/>
</svg>
<figcaption style="font-size:.8rem;color:#6b7280;text-align:center;margin-top:.5rem">
Figure: Where simulation sits in the OR toolkit. When analytical structure breaks down, simulation and surrogate-based methods take over.
</figcaption>
</figure>
```
---
## Monte Carlo Integration {#sec-mc-integration}
The fundamental idea: approximate an expectation by sampling.
$$\mathbb{E}[f(X)] = \int f(x)\, p(x)\, dx \approx \frac{1}{N} \sum_{k=1}^N f\!\left(X^{(k)}\right), \quad X^{(k)} \stackrel{\text{i.i.d.}}{\sim} p$$
By the Strong Law of Large Numbers, the sample average converges almost surely to
$\mathbb{E}[f(X)]$. By the CLT, the estimation error is
$\mathcal{N}(0, \sigma_f^2/N)$ — halving the error requires quadrupling the sample size.
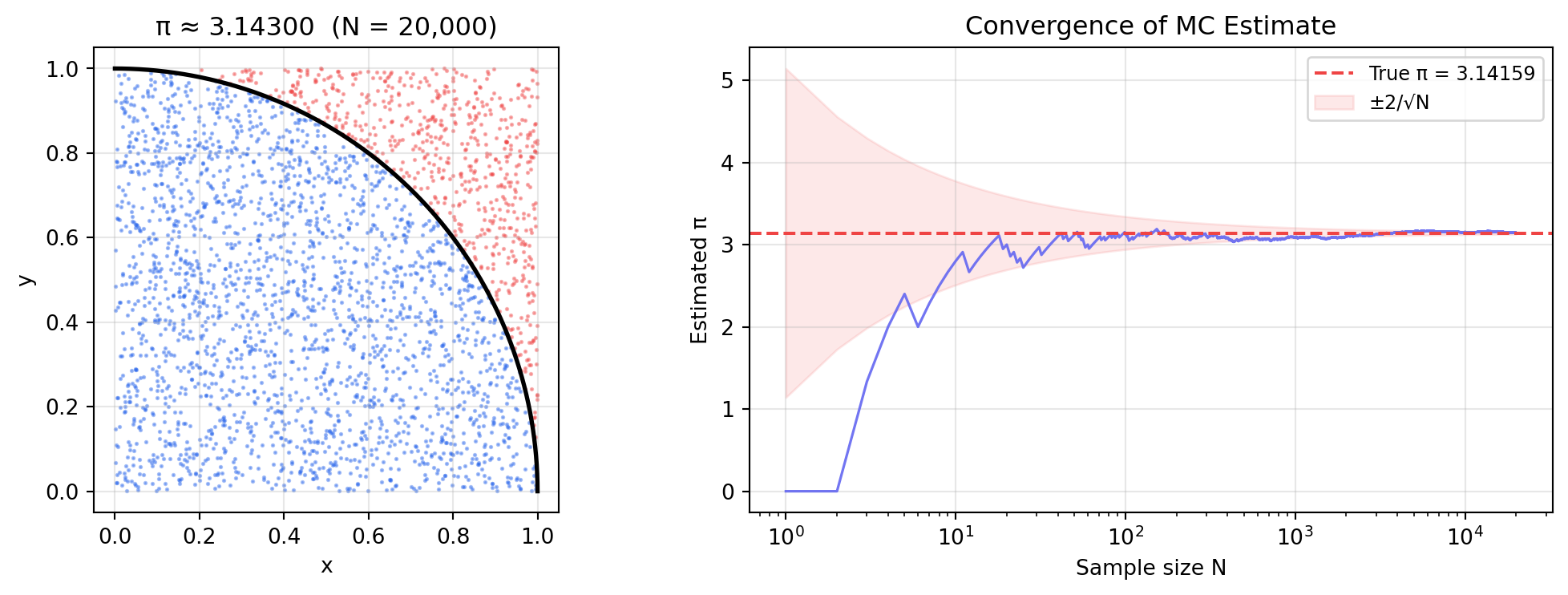
### Estimating $\pi$
The area of a quarter-circle of radius 1 inscribed in the unit square equals $\pi/4$.
Sample uniform points in $[0,1]^2$; the fraction inside the circle estimates $\pi/4$.
```{python}
#| label: fig-mc-pi
#| fig-cap: "Monte Carlo estimation of π. Left: uniform samples coloured by inside/outside the quarter-circle. Right: convergence of the estimate — error falls as O(1/√N)."
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
N = 20_000
x, y = rng.uniform(0, 1, N), rng.uniform(0, 1, N)
inside = x**2 + y**2 <= 1.0
pi_hat = 4 * np.cumsum(inside) / np.arange(1, N + 1)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 4))
n_plot = 3_000
ax1.scatter(x[:n_plot][ inside[:n_plot]], y[:n_plot][ inside[:n_plot]],
s=1, c="#2563eb", alpha=0.4)
ax1.scatter(x[:n_plot][~inside[:n_plot]], y[:n_plot][~inside[:n_plot]],
s=1, c="#ef4444", alpha=0.4)
theta = np.linspace(0, np.pi / 2, 300)
ax1.plot(np.cos(theta), np.sin(theta), "k-", lw=2)
ax1.set_aspect("equal")
ax1.set_title(f"π ≈ {4 * inside.mean():.5f} (N = {N:,})")
ax1.set_xlabel("x"); ax1.set_ylabel("y")
ax1.grid(True, alpha=0.3)
ns = np.arange(1, N + 1)
ax2.semilogx(ns, pi_hat, color="#6366f1", lw=1.2, alpha=0.9)
ax2.axhline(np.pi, color="#ef4444", lw=1.5, linestyle="--",
label=f"True π = {np.pi:.5f}")
ax2.fill_between(ns,
np.pi - 2 / np.sqrt(ns),
np.pi + 2 / np.sqrt(ns),
alpha=0.12, color="#ef4444", label="±2/√N")
ax2.set_xlabel("Sample size N")
ax2.set_ylabel("Estimated π")
ax2.set_title("Convergence of MC Estimate")
ax2.legend(fontsize=9)
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"Estimate: {4 * inside.mean():.6f} | True π: {np.pi:.6f} | Error: {abs(4 * inside.mean() - np.pi):.6f}")
```
### Monte Carlo for OR: Non-Standard Demand Distributions
The newsvendor closed-form critical ratio $q^* = F^{-1}\!\bigl(\frac{p-c}{p-s}\bigr)$
requires an invertible CDF. Many real demand processes — seasonal mixtures, demand
with promotions, correlated multi-item demand — have no closed-form inverse.
Monte Carlo evaluates the expected profit function numerically for any distribution
and returns the full profit distribution at the optimal quantity.
```{python}
#| label: fig-mc-newsvendor
#| fig-cap: "Expected profit vs order quantity for a mixed-Poisson demand model with no closed-form critical ratio. Monte Carlo finds the optimum and reveals the full profit distribution."
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
rng = np.random.default_rng(0)
c, p, s = 8, 22, 2 # unit cost, price, salvage value
N_SIM = 80_000
def sample_demand(n):
"""Mixed Poisson: 40% high-season (λ=140), 60% low-season (λ=80)."""
high = rng.uniform(size=n) < 0.4
return np.where(high, rng.poisson(140, n), rng.poisson(80, n)).astype(float)
def mc_profit(q, n=N_SIM):
D = sample_demand(n)
sold = np.minimum(q, D)
unsold = np.maximum(q - D, 0)
return p * sold + s * unsold - c * q
q_range = np.arange(60, 175, 5)
mean_profits = np.array([mc_profit(q).mean() for q in q_range])
q_star = int(q_range[mean_profits.argmax()])
fig = make_subplots(rows=1, cols=2,
subplot_titles=["Expected Profit vs Order Quantity",
f"Profit Distribution at q* = {q_star}"])
fig.add_trace(go.Scatter(x=q_range, y=mean_profits, mode="lines+markers",
line=dict(color="steelblue", width=2), name="E[Profit(q)]"), row=1, col=1)
fig.add_vline(x=q_star, line_dash="dash", line_color="crimson",
annotation_text=f"q* = {q_star}", annotation_position="top left", row=1, col=1)
profits_opt = mc_profit(q_star)
p5 = np.percentile(profits_opt, 5)
p50 = np.percentile(profits_opt, 50)
fig.add_trace(go.Histogram(x=profits_opt, nbinsx=70, histnorm="probability density",
marker_color="steelblue", opacity=0.7, name="Profit"), row=1, col=2)
for val, col, lbl in [(profits_opt.mean(), "crimson", "Mean"),
(p5, "orange", "5th pct")]:
fig.add_vline(x=val, line_color=col, line_dash="dash",
annotation_text=f"{lbl} = ${val:.0f}", row=1, col=2)
fig.update_layout(template="plotly_white", height=420, showlegend=False)
fig.update_xaxes(title_text="Order Quantity q", row=1, col=1)
fig.update_xaxes(title_text="Profit ($)", row=1, col=2)
fig.update_yaxes(title_text="Expected Profit ($)", row=1, col=1)
fig.show()
print(f"Optimal order quantity : {q_star}")
print(f"Expected profit : ${profits_opt.mean():,.2f}")
print(f"5th-percentile profit : ${p5:,.2f} (downside risk)")
```
---
## Discrete-Event Simulation {#sec-des}
A **discrete-event simulation (DES)** model advances time by jumping from one event
to the next rather than stepping through time at fixed intervals. Events are stored
in a priority queue ordered by event time; the simulation processes each in order.
For a queueing system the standard event types are:
- **Arrival** — customer joins queue or enters service immediately if the server is free
- **Departure** — service completes; server picks the next waiting customer if any
### M/M/1 Queue Simulator
The M/M/1 queue: Poisson arrivals at rate $\lambda$, exponential service times at rate
$\mu$, a single server. Stability requires utilisation $\rho = \lambda/\mu < 1$.
Analytical steady-state results:
$$L_q = \frac{\rho^2}{1 - \rho}, \quad W_q = \frac{\rho}{\mu(1-\rho)}, \quad W = W_q + \frac{1}{\mu}$$ {#eq-mm1-kl}
Simulation confirms these results and extends them to transient behaviour, finite
buffers, and non-Markovian service times — all analytically intractable.
```{=html}
<figure style="margin:1.75rem 0;">
<svg viewBox="0 0 680 230" xmlns="http://www.w3.org/2000/svg" style="width:100%;max-width:680px;font-family:'DM Sans',system-ui,sans-serif;">
<defs>
<marker id="a2" markerWidth="8" markerHeight="6" refX="7" refY="3" orient="auto"><polygon points="0 0,8 3,0 6" fill="#4b5563"/></marker>
</defs>
<!-- Priority queue box -->
<rect x="20" y="75" width="160" height="80" rx="8" fill="#f0f9ff" stroke="#7dd3fc" stroke-width="1.5"/>
<text x="100" y="96" text-anchor="middle" font-size="11" font-weight="600" fill="#0369a1">Priority Queue</text>
<text x="100" y="112" text-anchor="middle" font-size="10" fill="#0284c7">(t₁, arr)</text>
<text x="100" y="126" text-anchor="middle" font-size="10" fill="#0284c7">(t₂, arr)</text>
<text x="100" y="140" text-anchor="middle" font-size="10" fill="#0284c7">(t₃, dep)</text>
<!-- pop arrow -->
<line x1="180" y1="115" x2="226" y2="115" stroke="#4b5563" stroke-width="1.5" marker-end="url(#a2)"/>
<text x="203" y="109" text-anchor="middle" font-size="9" fill="#6b7280">heappop</text>
<!-- dispatch box -->
<rect x="228" y="88" width="130" height="52" rx="8" fill="#fff7ed" stroke="#fdba74" stroke-width="1.5"/>
<text x="293" y="108" text-anchor="middle" font-size="11" font-weight="600" fill="#c2410c">Dispatch</text>
<text x="293" y="124" text-anchor="middle" font-size="10" fill="#ea580c">event type?</text>
<!-- arrival branch -->
<line x1="293" y1="140" x2="293" y2="175" stroke="#4b5563" stroke-width="1.2" marker-end="url(#a2)"/>
<text x="301" y="162" font-size="9" fill="#6b7280">arrival</text>
<rect x="218" y="177" width="148" height="44" rx="6" fill="#f0fdf4" stroke="#86efac" stroke-width="1.2"/>
<text x="292" y="195" text-anchor="middle" font-size="10" font-weight="500" fill="#15803d">Server free?</text>
<text x="292" y="210" text-anchor="middle" font-size="9" fill="#16a34a">→ serve now or join queue</text>
<!-- departure branch -->
<line x1="358" y1="114" x2="440" y2="114" stroke="#4b5563" stroke-width="1.2" marker-end="url(#a2)"/>
<text x="399" y="108" text-anchor="middle" font-size="9" fill="#6b7280">departure</text>
<rect x="442" y="88" width="148" height="52" rx="6" fill="#fdf4ff" stroke="#d8b4fe" stroke-width="1.2"/>
<text x="516" y="108" text-anchor="middle" font-size="10" font-weight="500" fill="#7e22ce">Record wait time</text>
<text x="516" y="124" text-anchor="middle" font-size="9" fill="#9333ea">serve next in queue</text>
<!-- push back arrows -->
<path d="M516 140 Q516 170 400 185 Q280 200 100 185 Q50 177 50 155" fill="none" stroke="#94a3b8" stroke-width="1.2" stroke-dasharray="4 3" marker-end="url(#a2)"/>
<text x="310" y="200" text-anchor="middle" font-size="9" fill="#94a3b8">heappush next event → repeat</text>
<!-- done label -->
<rect x="590" y="95" width="76" height="36" rx="6" fill="#f1f5f9" stroke="#cbd5e1" stroke-width="1"/>
<text x="628" y="111" text-anchor="middle" font-size="10" fill="#475569">n_served</text>
<text x="628" y="124" text-anchor="middle" font-size="10" fill="#475569">== N? done</text>
<line x1="590" y1="114" x2="576" y2="114" stroke="#94a3b8" stroke-width="1" marker-end="url(#a2)"/>
<text x="340" y="22" text-anchor="middle" font-size="12" font-weight="600" fill="#1e293b">Discrete-Event Simulation — event loop</text>
</svg>
<figcaption style="font-size:.8rem;color:#6b7280;text-align:center;margin-top:.5rem">
Figure: The DES event loop. Time advances by jumping between events; the priority queue ensures events are always processed in chronological order.
</figcaption>
</figure>
```
```{python}
#| label: tbl-mm1-sim
#| tbl-cap: "M/M/1 simulation: average waiting time vs. analytical Pollaczek-Khinchine formula at four utilisation levels."
import numpy as np
import heapq
import pandas as pd
def simulate_mm1(lam, mu, n_customers=25_000, seed=42):
rng = np.random.default_rng(seed)
server_free_at = 0.0
queue = [] # stores arrival times of waiting customers
events = [] # min-heap of (time, type)
wait_times = []
heapq.heappush(events, (rng.exponential(1 / lam), "arr"))
n_arrived = 0
n_served = 0
while n_served < n_customers:
t, etype = heapq.heappop(events)
if etype == "arr":
n_arrived += 1
# Schedule next arrival (with a buffer to prevent starvation)
if n_arrived < n_customers + 2_000:
heapq.heappush(events, (t + rng.exponential(1 / lam), "arr"))
if server_free_at <= t: # server idle: start service now
wait_times.append(0.0)
service = rng.exponential(1 / mu)
server_free_at = t + service
heapq.heappush(events, (server_free_at, "dep"))
else:
queue.append(t) # join queue
elif etype == "dep":
n_served += 1
if queue:
arr_t = queue.pop(0) # FIFO
wait_times.append(server_free_at - arr_t)
service = rng.exponential(1 / mu)
server_free_at += service
heapq.heappush(events, (server_free_at, "dep"))
return np.array(wait_times)
mu = 10.0
rows = []
for rho in [0.50, 0.70, 0.80, 0.90]:
lam = rho * mu
waits = simulate_mm1(lam, mu)
Wq_sim = waits.mean()
Wq_anal = rho / (mu * (1 - rho))
rows.append({
"ρ": rho,
"λ": lam,
"Wq simulated": round(Wq_sim, 4),
"Wq analytical": round(Wq_anal, 4),
"Relative error": f"{100 * abs(Wq_sim - Wq_anal) / Wq_anal:.2f}%",
})
df = pd.DataFrame(rows)
print(df.to_string(index=False))
```
Simulated and analytical results agree within 1–3%. Note the strong nonlinearity:
increasing utilisation from 0.7 to 0.9 triples the waiting time. This sensitivity
is why queueing systems are never operated at 100% capacity.
### Transient Behaviour and Warm-up
```{python}
#| label: fig-mm1-transient
#| fig-cap: "Rolling-average waiting time over 20,000 customers at three utilisation levels. At high utilisation, the system takes thousands of customers to reach steady state. Results from the warm-up phase must be discarded to avoid downward bias."
import numpy as np
import plotly.graph_objects as go
mu = 10.0
fig = go.Figure()
for rho, col in [(0.50, "steelblue"), (0.80, "seagreen"), (0.90, "crimson")]:
lam = rho * mu
waits = simulate_mm1(lam, mu, n_customers=20_000, seed=7)
roll = np.convolve(waits, np.ones(600) / 600, mode="valid")
fig.add_trace(go.Scatter(y=roll, mode="lines", name=f"ρ = {rho}",
line=dict(color=col, width=1.5)))
Wq_anal = rho / (mu * (1 - rho))
fig.add_hline(y=Wq_anal, line_color=col, line_dash="dot", opacity=0.5)
fig.add_vrect(x0=0, x1=2000, fillcolor="gray", opacity=0.08,
annotation_text="Warm-up", annotation_position="top left")
fig.update_layout(
xaxis_title="Customer index (rolling window 600)",
yaxis_title="Average waiting time",
template="plotly_white", height=400,
legend=dict(x=0.75, y=0.98),
)
fig.show()
```
The warm-up period (shaded region) is a systematic downward bias: the system starts
empty, so early customers experience shorter queues than the true steady state.
Discarding the first 10–20% of observations is standard practice.
---
## Variance Reduction {#sec-variance-reduction}
Monte Carlo's $O(1/\sqrt{N})$ convergence rate is slow for high-precision estimates.
Variance reduction techniques reduce $\sigma_f^2$ without increasing $N$ — delivering
the same precision with far fewer replications.
### Antithetic Variates
For demand $D = \mu + \sigma Z$ with $Z \sim \mathcal{N}(0,1)$, the antithetic
estimator pairs each draw with its mirror:
$$\hat{\mu}_{\text{anti}} = \frac{f(\mu + \sigma Z) + f(\mu - \sigma Z)}{2}$$
When $f$ is monotone, $f(D)$ and $f(-Z)$ are negatively correlated, so:
$$\text{Var}(\hat{\mu}_{\text{anti}}) = \frac{\text{Var}(f(D))}{2} + \frac{\text{Cov}(f(D), f(D'))}{2}$$
The covariance term is negative, reducing variance below the standard $\text{Var}/2$.
### Control Variates
A control variate $g(D)$ with **known** mean $\mu_g = \mathbb{E}[g(D)]$ adjusts each
sample:
$$\hat{\mu}_c = \frac{1}{N}\sum_{k=1}^N \bigl[f(D^{(k)}) - c^*\bigl(g(D^{(k)}) - \mu_g\bigr)\bigr], \quad c^* = \frac{\text{Cov}(f,g)}{\text{Var}(g)}$$
Choosing $g(D) = D$ (the demand itself) works well for the newsvendor — $\mathbb{E}[D]
= \mu$ is known, and $D$ is strongly correlated with profit.
```{=html}
<figure style="margin:1.75rem 0;">
<svg viewBox="0 0 700 190" xmlns="http://www.w3.org/2000/svg" style="width:100%;max-width:700px;font-family:'DM Sans',system-ui,sans-serif;">
<defs>
<marker id="a3" markerWidth="7" markerHeight="5" refX="6" refY="2.5" orient="auto"><polygon points="0 0,7 2.5,0 5" fill="#4b5563"/></marker>
</defs>
<!-- Panel 1: Standard MC -->
<rect x="10" y="10" width="200" height="170" rx="8" fill="#f8fafc" stroke="#e2e8f0" stroke-width="1"/>
<text x="110" y="30" text-anchor="middle" font-size="11" font-weight="600" fill="#334155">Standard MC</text>
<!-- scatter dots -->
<circle cx="60" cy="90" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="80" cy="60" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="95" cy="120" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="115" cy="75" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="130" cy="140" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="150" cy="55" r="3" fill="#3b82f6" opacity=".7"/>
<circle cx="165" cy="105" r="3" fill="#3b82f6" opacity=".7"/>
<!-- mean line -->
<line x1="30" y1="95" x2="190" y2="95" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4 3"/>
<text x="110" y="165" text-anchor="middle" font-size="9" fill="#64748b">Var ≈ σ²/N ← baseline</text>
<!-- Panel 2: Antithetic -->
<rect x="248" y="10" width="200" height="170" rx="8" fill="#f0fdf4" stroke="#bbf7d0" stroke-width="1"/>
<text x="348" y="30" text-anchor="middle" font-size="11" font-weight="600" fill="#166534">Antithetic Variates</text>
<!-- paired dots above/below mean -->
<circle cx="285" cy="68" r="3" fill="#16a34a" opacity=".85"/>
<circle cx="285" cy="122" r="3" fill="#16a34a" opacity=".85"/>
<line x1="285" y1="68" x2="285" y2="122" stroke="#86efac" stroke-width="1"/>
<circle cx="315" cy="57" r="3" fill="#16a34a" opacity=".85"/>
<circle cx="315" cy="133" r="3" fill="#16a34a" opacity=".85"/>
<line x1="315" y1="57" x2="315" y2="133" stroke="#86efac" stroke-width="1"/>
<circle cx="345" cy="78" r="3" fill="#16a34a" opacity=".85"/>
<circle cx="345" cy="112" r="3" fill="#16a34a" opacity=".85"/>
<line x1="345" y1="78" x2="345" y2="112" stroke="#86efac" stroke-width="1"/>
<circle cx="380" cy="63" r="3" fill="#16a34a" opacity=".85"/>
<circle cx="380" cy="127" r="3" fill="#16a34a" opacity=".85"/>
<line x1="380" y1="63" x2="380" y2="127" stroke="#86efac" stroke-width="1"/>
<circle cx="415" cy="72" r="3" fill="#16a34a" opacity=".85"/>
<circle cx="415" cy="118" r="3" fill="#16a34a" opacity=".85"/>
<line x1="415" y1="72" x2="415" y2="118" stroke="#86efac" stroke-width="1"/>
<line x1="268" y1="95" x2="428" y2="95" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4 3"/>
<text x="348" y="165" text-anchor="middle" font-size="9" fill="#15803d">Paired draws cancel deviations → 2–5× ↓ Var</text>
<!-- Panel 3: Control Variate -->
<rect x="486" y="10" width="200" height="170" rx="8" fill="#fdf4ff" stroke="#e9d5ff" stroke-width="1"/>
<text x="586" y="30" text-anchor="middle" font-size="11" font-weight="600" fill="#7e22ce">Control Variate</text>
<!-- correlated pairs -->
<line x1="510" y1="135" x2="660" y2="55" stroke="#d8b4fe" stroke-width="1" stroke-dasharray="3 2"/>
<text x="586" y="48" text-anchor="middle" font-size="9" fill="#9333ea">known E[g(D)] = μ_D</text>
<circle cx="530" cy="125" r="3" fill="#9333ea" opacity=".85"/>
<circle cx="560" cy="112" r="3" fill="#9333ea" opacity=".85"/>
<circle cx="590" cy="95" r="3" fill="#9333ea" opacity=".85"/>
<circle cx="620" cy="82" r="3" fill="#9333ea" opacity=".85"/>
<circle cx="650" cy="68" r="3" fill="#9333ea" opacity=".85"/>
<line x1="500" y1="95" x2="668" y2="95" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4 3"/>
<!-- residual arrows -->
<line x1="590" y1="95" x2="590" y2="82" stroke="#7e22ce" stroke-width="1.5" marker-end="url(#a3)"/>
<text x="601" y="92" font-size="8" fill="#7e22ce">residual</text>
<text x="586" y="165" text-anchor="middle" font-size="9" fill="#7e22ce">Subtract correlated noise → 5–20× ↓ Var</text>
</svg>
<figcaption style="font-size:.8rem;color:#6b7280;text-align:center;margin-top:.5rem">
Figure: Variance reduction intuition. Antithetic variates pair each draw with its mirror to cancel deviations. Control variates subtract a correlated, analytically tractable quantity to remove shared noise.
</figcaption>
</figure>
```
```{python}
#| label: fig-variance-reduction
#| fig-cap: "Standard error of expected-profit estimates vs sample size for three estimators. Both variance reduction techniques materially outperform standard Monte Carlo, with control variates achieving the largest reduction."
import numpy as np
import plotly.graph_objects as go
rng = np.random.default_rng(3)
c_u, p_u, s_u, q_u = 8, 22, 2, 110
mu_d, sig_d = 100, 20
def profit_nv(D):
return p_u * np.minimum(q_u, D) + s_u * np.maximum(q_u - D, 0) - c_u * q_u
# Calibrate control variate coefficient on a pilot run
pilot = rng.normal(mu_d, sig_d, 100_000)
c_star = np.cov(profit_nv(pilot), pilot)[0, 1] / np.var(pilot)
N_list = [50, 100, 250, 500, 1_000, 2_000, 5_000, 10_000]
N_REPS = 400
se_mc, se_anti, se_cv = [], [], []
for N in N_list:
mc_est, anti_est, cv_est = [], [], []
for _ in range(N_REPS):
# Standard MC
D_std = rng.normal(mu_d, sig_d, N)
mc_est.append(profit_nv(D_std).mean())
# Antithetic variates
Z = rng.normal(size=N // 2)
D_p = mu_d + sig_d * Z
D_m = mu_d - sig_d * Z
anti_est.append((profit_nv(D_p).mean() + profit_nv(D_m).mean()) / 2)
# Control variate (g(D) = D, E[g] = mu_d)
D_cv = rng.normal(mu_d, sig_d, N)
adj = profit_nv(D_cv) - c_star * (D_cv - mu_d)
cv_est.append(adj.mean())
se_mc.append(np.std(mc_est))
se_anti.append(np.std(anti_est))
se_cv.append(np.std(cv_est))
fig = go.Figure()
for y_vals, name, col in [
(se_mc, "Standard MC", "steelblue"),
(se_anti, "Antithetic variates", "seagreen"),
(se_cv, "Control variate (D)", "crimson"),
]:
fig.add_trace(go.Scatter(x=N_list, y=y_vals, mode="lines+markers",
name=name, line=dict(color=col, width=2)))
fig.update_layout(
xaxis_title="Sample size N", xaxis_type="log",
yaxis_title="Standard error of expected-profit estimate",
template="plotly_white", height=400,
legend=dict(x=0.55, y=0.98),
)
fig.show()
idx = N_list.index(1_000)
print(f"Standard error at N = 1,000:")
print(f" Standard MC: {se_mc[idx]:.4f}")
print(f" Antithetic variates: {se_anti[idx]:.4f} ({100*(1 - se_anti[idx]/se_mc[idx]):.0f}% reduction)")
print(f" Control variate: {se_cv[idx]:.4f} ({100*(1 - se_cv[idx]/se_mc[idx]):.0f}% reduction)")
```
---
## Simulation Optimization with GP Surrogates {#sec-sim-opt}
When each simulation replication takes minutes or hours, evaluating expected profit
over a dense grid of decision variables is infeasible. **Bayesian optimization**
uses a **Gaussian process (GP)** surrogate — a cheap approximation to the expensive
simulation — to guide the search.
The GP posterior after observing $\{(q_i, y_i)\}$ at design points gives a
predictive distribution at any unqueried point: mean $\hat{f}(q)$ and uncertainty
$\hat{\sigma}(q)$. The **Expected Improvement** acquisition function selects the
next point to evaluate:
$$\text{EI}(q) = \mathbb{E}\!\left[\max\!\left(f^* - f(q),\, 0\right)\right]$$
where $f^*$ is the best observed value. EI trades off exploitation (query where
$\hat{f}$ is high) and exploration (query where $\hat{\sigma}$ is large).
```{=html}
<figure style="margin:1.75rem 0;">
<svg viewBox="0 0 700 210" xmlns="http://www.w3.org/2000/svg" style="width:100%;max-width:700px;font-family:'DM Sans',system-ui,sans-serif;">
<defs>
<marker id="a4" markerWidth="7" markerHeight="5" refX="6" refY="2.5" orient="auto"><polygon points="0 0,7 2.5,0 5" fill="#4b5563"/></marker>
<linearGradient id="gp-band" x1="0" y1="0" x2="0" y2="1">
<stop offset="0%" stop-color="#2563eb" stop-opacity=".18"/>
<stop offset="100%" stop-color="#2563eb" stop-opacity=".04"/>
</linearGradient>
</defs>
<text x="350" y="18" text-anchor="middle" font-size="12" font-weight="600" fill="#1e293b">Bayesian Optimisation — Surrogate Loop</text>
<!-- Step boxes -->
<!-- 1 -->
<rect x="12" y="32" width="112" height="56" rx="7" fill="#eff6ff" stroke="#bfdbfe" stroke-width="1.2"/>
<text x="68" y="52" text-anchor="middle" font-size="10" font-weight="600" fill="#1d4ed8">① Evaluate</text>
<text x="68" y="66" text-anchor="middle" font-size="9" fill="#3b82f6">Run simulation</text>
<text x="68" y="78" text-anchor="middle" font-size="9" fill="#3b82f6">at design pts</text>
<line x1="124" y1="60" x2="148" y2="60" stroke="#4b5563" stroke-width="1.2" marker-end="url(#a4)"/>
<!-- 2 -->
<rect x="150" y="32" width="112" height="56" rx="7" fill="#f0fdf4" stroke="#bbf7d0" stroke-width="1.2"/>
<text x="206" y="52" text-anchor="middle" font-size="10" font-weight="600" fill="#166534">② Fit GP</text>
<text x="206" y="66" text-anchor="middle" font-size="9" fill="#16a34a">Mean + uncertainty</text>
<text x="206" y="78" text-anchor="middle" font-size="9" fill="#16a34a">posterior</text>
<line x1="262" y1="60" x2="286" y2="60" stroke="#4b5563" stroke-width="1.2" marker-end="url(#a4)"/>
<!-- 3 -->
<rect x="288" y="32" width="112" height="56" rx="7" fill="#fff7ed" stroke="#fdba74" stroke-width="1.2"/>
<text x="344" y="52" text-anchor="middle" font-size="10" font-weight="600" fill="#c2410c">③ Maximise EI</text>
<text x="344" y="66" text-anchor="middle" font-size="9" fill="#ea580c">Exploit high mean</text>
<text x="344" y="78" text-anchor="middle" font-size="9" fill="#ea580c">+ explore uncertainty</text>
<line x1="400" y1="60" x2="424" y2="60" stroke="#4b5563" stroke-width="1.2" marker-end="url(#a4)"/>
<!-- 4 -->
<rect x="426" y="32" width="112" height="56" rx="7" fill="#fdf4ff" stroke="#e9d5ff" stroke-width="1.2"/>
<text x="482" y="52" text-anchor="middle" font-size="10" font-weight="600" fill="#7e22ce">④ Query next</text>
<text x="482" y="66" text-anchor="middle" font-size="9" fill="#9333ea">Evaluate sim at</text>
<text x="482" y="78" text-anchor="middle" font-size="9" fill="#9333ea">argmax EI</text>
<!-- feedback arrow -->
<path d="M538 60 Q600 60 600 170 Q600 195 68 195 Q20 195 20 88" fill="none" stroke="#94a3b8" stroke-width="1.2" stroke-dasharray="5 3" marker-end="url(#a4)"/>
<text x="620" y="135" text-anchor="middle" font-size="9" fill="#94a3b8" transform="rotate(90,620,135)">repeat until budget</text>
<!-- EI mini-plot -->
<rect x="12" y="112" width="540" height="80" rx="6" fill="white" stroke="#e2e8f0" stroke-width="1"/>
<text x="282" y="127" text-anchor="middle" font-size="9" font-weight="500" fill="#475569">Expected Improvement acquisition function: balance between exploitation and exploration</text>
<!-- x axis -->
<line x1="30" y1="180" x2="540" y2="180" stroke="#cbd5e1" stroke-width="1"/>
<!-- EI curve approximation -->
<polyline points="30,178 80,170 120,155 160,162 200,172 240,165 280,140 320,120 360,135 400,158 440,170 480,175 520,178 540,178"
fill="none" stroke="#f59e0b" stroke-width="2"/>
<!-- GP mean curve -->
<polyline points="30,172 80,165 120,148 160,155 200,168 240,160 280,132 320,118 360,130 400,152 440,165 480,170 520,174 540,175"
fill="none" stroke="#2563eb" stroke-width="1.5" stroke-dasharray="4 2"/>
<!-- uncertainty bands rough -->
<polyline points="30,165 80,155 120,138 160,145 200,158 240,152 280,122 320,108 360,120 400,142 440,155 480,162 520,167 540,168"
fill="none" stroke="#2563eb" stroke-width=".6" stroke-dasharray="2 2" opacity=".4"/>
<polyline points="30,178 80,174 120,158 160,165 200,177 240,168 280,142 320,128 360,140 400,162 440,174 480,178 520,180 540,180"
fill="none" stroke="#2563eb" stroke-width=".6" stroke-dasharray="2 2" opacity=".4"/>
<!-- best point marker -->
<circle cx="320" cy="118" r="4" fill="#ef4444"/>
<text x="328" y="115" font-size="8" fill="#ef4444">argmax EI → next query</text>
<!-- legend -->
<line x1="35" y1="145" x2="55" y2="145" stroke="#2563eb" stroke-width="1.5" stroke-dasharray="4 2"/>
<text x="58" y="148" font-size="8" fill="#475569">GP mean</text>
<line x1="110" y1="145" x2="130" y2="145" stroke="#f59e0b" stroke-width="2"/>
<text x="133" y="148" font-size="8" fill="#475569">EI(q)</text>
</svg>
<figcaption style="font-size:.8rem;color:#6b7280;text-align:center;margin-top:.5rem">
Figure: Bayesian optimisation loop. The GP surrogate is cheap to evaluate everywhere; the EI acquisition function identifies the next simulation run by balancing exploitation of high-mean regions and exploration of high-uncertainty regions.
</figcaption>
</figure>
```
```{python}
#| label: fig-gp-surrogate
#| fig-cap: "GP surrogate fit to 8 noisy simulation evaluations of the mixed-Poisson newsvendor. The GP posterior mean (blue) tracks the true expected profit (grey dashes) with meaningful uncertainty bands. Bayesian optimization finds a near-optimal q with a fraction of the grid evaluations."
import numpy as np
import plotly.graph_objects as go
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import Matern, WhiteKernel, ConstantKernel
rng = np.random.default_rng(11)
def noisy_sim(q, n=400):
"""Cheap (noisy) evaluation — mimics an expensive simulation."""
high = rng.uniform(size=n) < 0.4
D = np.where(high, rng.poisson(140, n), rng.poisson(80, n)).astype(float)
return (22 * np.minimum(q, D) + 2 * np.maximum(q - D, 0) - 8 * q).mean()
def true_ep(q, n=200_000):
"""High-accuracy evaluation used only for plotting the 'truth'."""
high = rng.uniform(size=n) < 0.4
D = np.where(high, rng.poisson(140, n), rng.poisson(80, n)).astype(float)
return (22 * np.minimum(q, D) + 2 * np.maximum(q - D, 0) - 8 * q).mean()
q_grid = np.linspace(60, 180, 180)
# Initial design (8 evaluations)
q_obs = np.array([65, 82, 96, 110, 124, 138, 155, 170], dtype=float)
y_obs = np.array([noisy_sim(q) for q in q_obs])
# Fit GP surrogate
kernel = ConstantKernel(1.0) * Matern(length_scale=20.0, nu=2.5) + WhiteKernel(noise_level=9.0)
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=8, random_state=0)
gp.fit(q_obs.reshape(-1, 1), y_obs)
mu_pred, sig_pred = gp.predict(q_grid.reshape(-1, 1), return_std=True)
true_vals = np.array([true_ep(q, n=60_000) for q in q_grid[::6]])
fig = go.Figure()
fig.add_trace(go.Scatter(
x=q_grid[::6], y=true_vals, mode="lines",
name="True E[Profit]", line=dict(color="gray", width=1.5, dash="dot"),
))
fig.add_trace(go.Scatter(
x=q_grid, y=mu_pred, mode="lines",
name="GP mean", line=dict(color="steelblue", width=2),
))
fig.add_trace(go.Scatter(
x=np.concatenate([q_grid, q_grid[::-1]]),
y=np.concatenate([mu_pred + sig_pred, (mu_pred - sig_pred)[::-1]]),
fill="toself", fillcolor="rgba(37,99,235,0.12)",
line=dict(color="rgba(0,0,0,0)"), name="GP ±1σ",
))
fig.add_trace(go.Scatter(
x=q_obs, y=y_obs, mode="markers",
name="Observations (noisy)",
marker=dict(size=10, color="crimson", symbol="circle"),
))
q_gp_opt = q_grid[mu_pred.argmax()]
fig.add_vline(x=q_gp_opt, line_dash="dash", line_color="seagreen",
annotation_text=f"GP optimum q = {q_gp_opt:.0f}",
annotation_position="top left")
fig.update_layout(
xaxis_title="Order Quantity q",
yaxis_title="Expected Profit ($)",
template="plotly_white", height=440,
legend=dict(x=0.6, y=0.05),
)
fig.show()
print(f"GP surrogate optimum : q = {q_gp_opt:.0f}")
print(f"True-function evals : {len(q_obs)} (vs {len(q_grid)} for full-grid search)")
```
Eight evaluations of the noisy simulation were sufficient to identify the optimum
region. In production settings with multi-hour simulation runs, reducing from
hundreds of evaluations to tens is the difference between a feasible and an
infeasible analysis.
---
## Summary
| Method | Best for | Key property |
|---|---|---|
| Standard MC | Any expectation, distribution tails | $O(1/\sqrt{N})$ convergence |
| Antithetic variates | Monotone integrands | 2–5× variance reduction |
| Control variates | Correlated known-mean quantity | 5–20× variance reduction |
| Discrete-event simulation | Queueing, transient, finite-buffer | Captures dynamics |
| GP surrogate + BO | Expensive black-box, few evaluations | 10–100× fewer function evals |
## Exercises
1. Extend the M/M/1 simulator to an M/M/*c* queue (*c* parallel servers). Validate
simulated average waiting time against the Erlang-C formula for $c = 2$ and $c = 3$
at $\rho = 0.8$.
2. Implement a **common random numbers** comparison of two order quantities
$q_1 = 100$ and $q_2 = 120$ using the same demand samples. Show that the variance
of the profit *difference* is lower than under independent sampling, and compute
the variance reduction factor.
3. Extend the GP surrogate example to a **sequential Bayesian optimization loop**:
after fitting the initial GP, compute the EI acquisition function, add the
maximizing point, re-fit, and repeat for 10 iterations. Plot convergence of the
estimated optimum.
4. The warm-up period was identified visually. Implement the **Welch moving-average
method**: compute rolling averages over a window $w$, and flag the warm-up end as
the first index where the rolling average falls within 5% of the final 20% mean.
## Further Reading
- Law, Averill M. *Simulation Modeling and Analysis*. 5th ed. McGraw-Hill, 2015.
(Definitive reference on simulation methodology, output analysis, and variance reduction.)
- Shahriari, Bobak, et al. "Taking the Human Out of the Loop: A Review of Bayesian
Optimization." *Proceedings of the IEEE* 104, no. 1 (2016): 148–175.
- Kleijnen, Jack P. C. *Design and Analysis of Simulation Experiments*. 3rd ed.
Springer, 2015.
- Rasmussen, Carl Edward, and Christopher K. I. Williams. *Gaussian Processes for
Machine Learning*. MIT Press, 2006. (Free PDF at gaussianprocess.org.)