| Concept | Latin | Greek | Sanskrit | English | PIE* | |
|---|---|---|---|---|---|---|
| 0 | father | pater | patḗr | pitar | father | *ph₂tḗr |
| 1 | water | aqua | hydōr | udaka | water | *wed- |
| 2 | night | nox | nýks | nakta | night | *nókʷts |
| 3 | fire | ignis | pŷr | agni | fire | *h₁ngʷni |
| 4 | star | stella | astḗr | tara | star | *h₂stḗr |
Etymology + Data Science
A Computational Survey of Word Origins
1 What Is Etymology? A Data Perspective
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Define etymology and explain what distinguishes it from ordinary vocabulary study
- Describe the comparative method in plain English
- Identify cognates in a wordlist using pattern recognition
- Frame the five core problems of computational etymology as data science tasks
- Write basic Python code to explore a multilingual wordlist
1.1 The Detective Problem
In 1786, a British judge named William Jones stood up at the Asiatic Society in Calcutta and delivered what may be the most consequential sentence ever spoken at an academic dinner. Having spent years studying Sanskrit—the ancient liturgical language of India—he announced that Sanskrit bore “a stronger affinity” to Greek and Latin “than could possibly have been produced by accident.” So strong was this affinity, he suggested, that all three languages must have descended from a common source.
The sentence launched a century of scholarship. Within fifty years, scholars across Europe had worked out the main skeleton of the Indo-European language family: Sanskrit, Greek, Latin, Gothic, Old Persian, Lithuanian, Old Slavic—all cousins, all descended from a proto-language no one had ever written down, spoken by people who left no other records. The method they used was the comparative method, and it remains, in its essentials, the foundation of etymology today.
What Jones had noticed—what the Sanskrit word pitar, the Greek patḗr, and the Latin pater share—is something more than a family resemblance. The sounds correspond systematically. The p at the start, the vowel, the t in the middle, the r at the end: these are not random coincidences. They are the fingerprints of a common ancestor.
That is what etymology studies. Not just where words come from, but why they look the way they do, and how you can infer the answer from patterns that survive across languages.
1.2 Why Words Have Histories Worth Studying
Before we get to algorithms, it is worth spending a moment on why any of this matters. Etymology can seem like an elaborate parlor game—impressive at dinner parties, useless for anything practical. This impression is wrong in at least three ways.
It is evidence about human prehistory. Before writing, before pottery we can radiocarbon-date, before almost anything else, there was language. Words carry information about the world their speakers inhabited. Proto-Indo-European, the ancestor of languages from Iceland to Bangladesh, had words for snow, for wheel, for cattle, for the number one hundred. It lacked a word for ocean. From this, linguists infer that its speakers lived inland, in a temperate climate, sometime before roughly 3500 BCE when wheeled vehicles first appeared in the archaeological record. Etymology is archaeology conducted through language—slower, more ambiguous, but capable of reaching places where no shovel can go.
It explains why languages look the way they do. English is a notoriously difficult language to learn. Why is knight spelled with a k and a gh that have been silent for five hundred years? Because when the spelling was fixed, those sounds were still pronounced: Middle English speakers said something like kni-cht, rhyming roughly with the Scottish loch. The spelling is a fossil. Most of the bizarre irregularities of English orthography, French grammar, and German word order make sense once you know the history. Etymology does not just explain the past; it makes the present legible.
It is a testing ground for computational linguistics. The problems of historical linguistics—comparing sequences, inferring hidden variables from observable ones, building trees from similarity data—are mathematically clean versions of problems that appear everywhere in NLP. Sequence alignment in etymology is the same algorithm as sequence alignment in bioinformatics, and closely related to the alignment step in machine translation. Phylogenetic inference in linguistics is the same mathematical procedure used to reconstruct evolutionary trees in genomics. Learning etymology computationally is, among other things, learning the shared substrate of a dozen applied fields.
1.3 A Brief History of the Science
William Jones’s 1786 dinner speech was the spark, but the fire had been building for decades. European scholars who had learned Sanskrit while working for the East India Company had been privately noting its resemblance to Latin and Greek for years; Jones simply said it publicly, at sufficient volume, to the right audience.
What followed was one of the most productive fifty years in the history of science—not well remembered, because it produced nothing dramatic like a device or a vaccine, only the reorganization of what people knew about the past. Rasmus Rask, a Danish linguist working in the 1810s, established the systematic sound correspondences between Old Norse, Gothic, Greek, and Latin. Jakob Grimm—better known today for the fairy tales he collected with his brother—formalized the Germanic consonant shift in 1822 in what became Grimm’s Law. Franz Bopp showed that Sanskrit, Greek, Latin, Gothic, and Persian all shared the same verb conjugation system, and that this shared structure was too detailed to be coincidence.
By 1870, the field had cohered into something recognizable as a discipline. A group of young German scholars calling themselves the Junggrammatiker—the Neogrammarians—made a provocative claim: sound changes are exceptionless. Not mostly regular. Not regular with some exceptions. Exceptionless, operating on the physics of articulation rather than the meaning of words. This was controversial enough that their older colleagues accused them of recklessness. It turned out to be substantially correct, and the principle of regularity became the discipline’s bedrock.
The twentieth century brought refinement but not revolution: better statistical methods, larger datasets, more languages documented before they vanished. The twenty-first century brought something more transformative: machine learning systems that could handle the scale that hand methods could not.
1.4 The Scale Problem
Here is the uncomfortable arithmetic of historical linguistics. The world has approximately 7,000 living languages. Of these, perhaps 500 have been studied to the point where a competent descriptive grammar exists. Fewer than 200 have been analyzed with the depth needed for serious comparative work. The rest—the vast majority—are documented at the level of a word list and a handful of texts, if that.
Languages are going extinct faster than linguists can document them. By the end of this century, the most optimistic estimates suggest that 3,000 of the world’s 7,000 languages will have gone silent. Each extinction takes with it not just words but a unique way of encoding human experience—and a unique source of data for the comparative method.
This is where computational etymology is not merely convenient but necessary. A human linguist working with the comparative method can analyze perhaps one language family in a career. Automated systems, once trained, can process thousands of language pairs in hours. The cognate detectors and proto-reconstructors we build in this book are not toys; they are the infrastructure of an emergency documentation effort operating against a deadline.
The 2010s and 2020s saw the field accelerate rapidly. The CLDF (Cross-Linguistic Data Formats) initiative standardized data collection across research groups. Automated cognate detection reached expert-level accuracy on benchmark tasks. Neural proto-reconstruction produced credible ancestral forms for entire language families. Phylogenetic inference using Bayesian methods dated the Indo-European expansion with precision that surprised even specialists. The methods of this book are not speculative; they are the working tools of active research.
The comparative method can be summarized in three steps.
Step 1: Gather cognates. A cognate is a pair of words in different languages that descend from the same ancestral word. English night and German Nacht are cognates. English night and French nuit are also cognates—both descend from the Latin nox, which descends further from the Proto-Indo-European root *nókʷts. Cognates are not the same as loanwords: English beef comes from French bœuf, but that is borrowing, not shared descent. The distinction matters.
Step 2: Identify sound correspondences. When you line up cognates across multiple languages, patterns emerge. Latin p systematically corresponds to English f in the same word positions. Latin pater, English father; Latin piscis, English fish; Latin pes/ped-, English foot. This is Grimm’s Law—a systematic shift of stops to fricatives that swept through the Germanic languages roughly two thousand years ago, like a wave passing through water.
Step 3: Reconstruct the proto-form. Given enough cognates and enough correspondences, you can infer what the ancestral form must have looked like. The asterisk (*) marks reconstructed forms—words no one ever recorded, deduced entirely from their surviving descendants. The fact that such deductions can be verified against actual discoveries (when ancient texts surface) is what makes the comparative method science rather than educated guessing.
1.5 Etymology as Data
Here is where things get interesting.
Notice what the comparative method is actually doing. It is taking a set of strings—words, transcribed as sequences of sounds—and detecting patterns of similarity and difference across them. It is grouping those strings by hypothesized ancestry. It is inferring hidden variables (the proto-forms) from observable ones (the modern words). It is, in short, doing data science on a structured dataset.
The dataset in question is a wordlist: a table where rows are concepts (FATHER, WATER, NIGHT, FIRE) and columns are languages, with cells containing the word for that concept in that language. This is the fundamental data structure of historical linguistics, and it is, conveniently, exactly the kind of tabular data that Python’s pandas library was designed to handle.
Look at the column for FATHER. Every entry except FIRE shares a recognizable similarity—the p/f at the start, the vowel in the middle, the t/th sound, the final r. FIRE is the odd one out: the Latin, Greek, and Sanskrit forms look nothing like each other, which suggests different roots, not a shared ancestor for this particular word.
This is already a data analysis task: spotting which cells cluster with which other cells, and which are outliers. A trained linguist can do it by eye. A computer can do it at scale, across a hundred languages and ten thousand concepts, in seconds.
1.6 The Five Core Problems
Computational etymology is organized around five problems, each of which maps cleanly onto a class of data science methods:
Problem 1: Cognate detection. Given a pair of words from different languages, are they related by descent? This is a binary classification problem. Input: two word strings (or sequences of phonemes). Output: cognate or not. We will spend Chapter 5 building a classifier for this.
Problem 2: Sequence alignment. When two cognates are identified, how do we align their sounds to identify which phoneme corresponds to which? English night [naɪt] and German Nacht [naxt]—the n matches n, the vowel has drifted, the final t matches t. But how do you determine that alignment algorithmically, especially when one word has more sounds than the other? This is a sequence alignment problem, borrowed directly from bioinformatics. Chapter 4.
Problem 3: Phylogenetic inference. Given a set of languages and their cognate relationships, what is the most likely family tree? This is a tree inference problem. The same algorithms that evolutionary biologists use to reconstruct the evolutionary tree of species apply, with modifications, to languages. Chapter 6.
Problem 4: Proto-form reconstruction. Given aligned cognates across multiple modern languages, can we predict the ancestral proto-form? This is a sequence-to-sequence prediction problem—the kind that neural networks handle well. Chapter 7.
Problem 5: Semantic drift. Words change meaning over time. “Awful” once meant awe-inspiring; now it means terrible. “Nice” once meant foolish; now it means pleasant. Can we detect and quantify this drift using word embeddings trained on historical text corpora? Chapter 8.
1.7 Why Machine Learning Changes Everything
The traditional comparative method works beautifully—for languages with large amounts of recorded history, spoken by cultures that kept written records, studied by teams of dedicated scholars over a century or more. But the world has approximately seven thousand living languages. Only a few hundred have been studied in any depth. Thousands more are vanishing without documentation.
Machine learning does not replace the comparative method. It scales it. A cognate detector trained on well-studied language families can be applied to underdocumented ones. A neural proto-reconstructor trained on Romance language data generalizes to other families with appropriate retraining. The algorithms are not magic—they carry assumptions baked in from their training data—but they extend the reach of historical linguistics into territory that hand methods alone could never cover.
The reverse transfer also runs. Etymology turns out to be an exceptionally good training ground for linguistic data science. The problems are well-defined, the ground truth is knowable, and the data has a satisfying structure. Concepts learned here—sequence alignment, phylogenetic inference, distributional semantics—transfer directly to speech recognition, machine translation, and clinical NLP.
One specific example illustrates the difference in scale. In 2018, a team at the Max Planck Institute for the Science of Human History published an automated analysis of Indo-European language relationships using a dataset of 52 languages and 208 Swadesh concepts—10,816 data cells in total. A human expert working by hand could analyze perhaps 50 language pairs per year in serious depth; the automated pipeline processed all \(\binom{52}{2} = 1326\) pairs in an afternoon, with accuracy competitive with expert annotation. The result was a phylogenetic tree that agreed with the expert consensus on major groupings and suggested a divergence timeline consistent with the Pontic steppe hypothesis for Indo-European origins.
This is the pattern throughout the field: automation does not exceed human accuracy on a single well-studied pair, but it closes the gap enough to be scientifically useful while operating at a scale that human effort simply cannot match. The tools of this book put that capability in your hands.
1.8 Your First Wordlist
Let us build the first practical object of this book: a multilingual wordlist in Python.
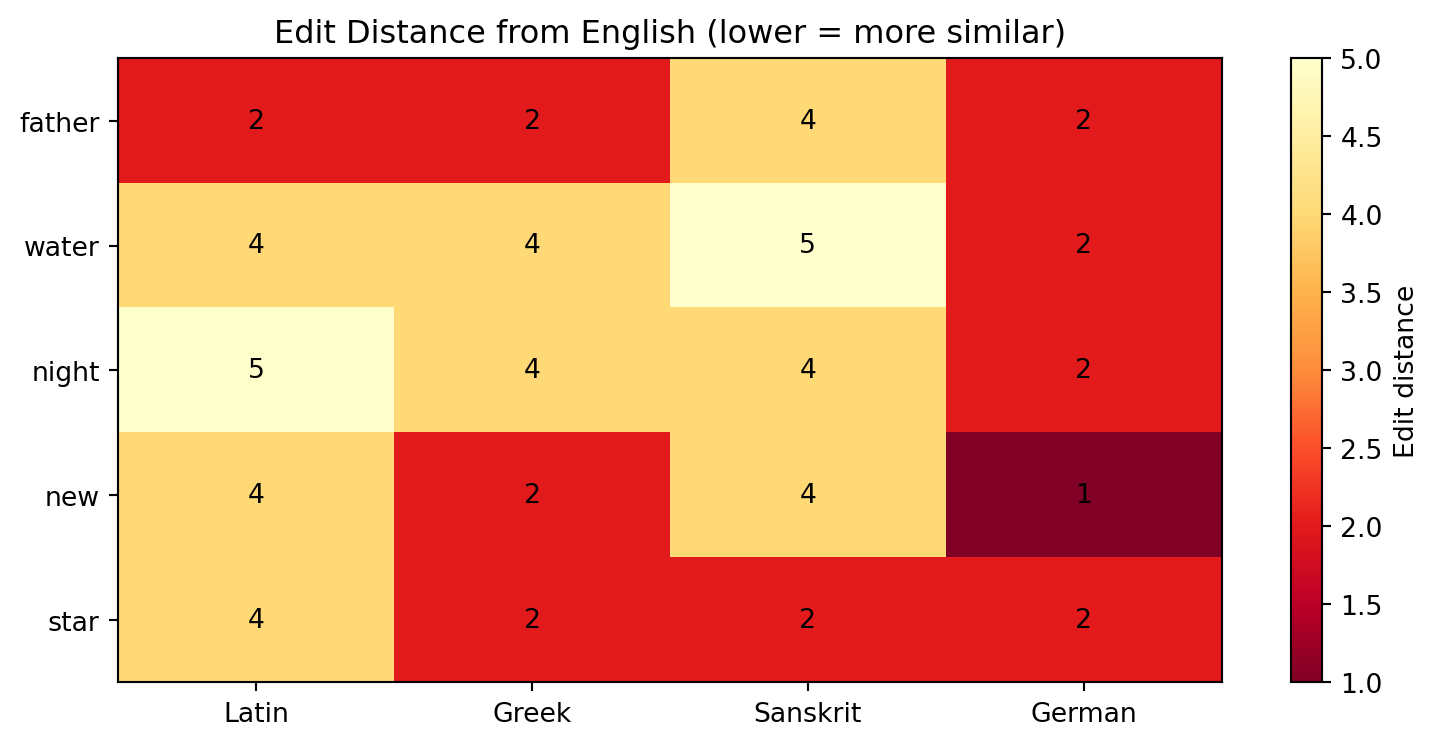
The heatmap already tells a story. FATHER and NEW show consistently low edit distances—the words are recognizably similar across all four comparison languages. NIGHT is a medium case. WATER is the outlier: aqua and hydor look nothing like the English word because the Germanic languages preserved one Indo-European root (*wed-) while Latin and Greek preserve different ones.
This is, in miniature, exactly the pattern-detection that the comparative method does at scale. And this is, in miniature, the kind of exploratory analysis you will do throughout this book—start with the data, visualize it, let the pattern lead you to the hypothesis.
1.9 Summary
Etymology studies the origin and historical development of words. The comparative method—identifying cognates, mapping sound correspondences, and reconstructing proto-forms—has been the core tool of historical linguistics for two centuries. Computational approaches do not replace this method; they automate and scale it. The five core problems (cognate detection, sequence alignment, phylogenetic inference, proto-form reconstruction, and semantic drift tracking) each map onto established data science techniques. The data structure underlying all of this is the multilingual wordlist: a table of concepts by languages, with each cell containing a phonetically transcribed word.
The remaining chapters build these tools, one layer at a time.
1.10 Further Reading
- Jones, W. (1786). The third anniversary discourse to the Asiatic Society. The speech that started it all.
- Campbell, L. (2013). Historical Linguistics: An Introduction (3rd ed.). MIT Press. The standard textbook reference for the comparative method.
- List, J.-M., Greenhill, S., & Gray, R. (2017). The potential of automatic word comparison for historical linguistics. PLOS ONE. A good overview of the computational turn in the field.
- Etymonline.com — for exploratory etymological browsing, nothing beats it.