4 Representing Language as Data
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Read and write basic IPA transcriptions for common sounds
- Describe phonemes in terms of articulatory features (voicing, place, manner)
- Load and manipulate a CLDF-format wordlist in Python
- Represent a phoneme as a binary feature vector
- Identify common data quality issues in linguistic datasets
- Segment a transcribed word into its component phonemes
4.1 The Alphabet Problem
When the phone company needed to determine whether two spoken words were the same, it did not read the spelling. It analyzed the acoustic waveform—the pressure signature of air molecules vibrating against a microphone. Spelling, it turns out, is an extremely poor proxy for sound. English alone has twenty-six letters representing roughly forty-four phonemes, with vowels that change meaning without warning (bat, bate, bait, beat, bit) and consonants that double without doubling their sound (kitten has one t sound, not two).
For a human who has been reading English since childhood, this ambiguity is invisible—we have learned to decode it automatically. For a computer, it is a disaster. If we want to analyze language as sound, we cannot use orthography. We need a different alphabet.
That alphabet exists. It is the International Phonetic Alphabet (IPA), designed in 1888 and now maintained by the International Phonetic Association. Its governing principle is one-to-one correspondence: every symbol represents exactly one sound, every sound is represented by exactly one symbol. Whether you are transcribing Mandarin tones, Arabic gutturals, or the click consonants of isiZulu, the IPA has a symbol for it.
4.2 The IPA Essentials
You do not need to memorize the full IPA chart to work through this book. You do need to recognize its structure and be comfortable with the sounds that appear in Indo-European languages.
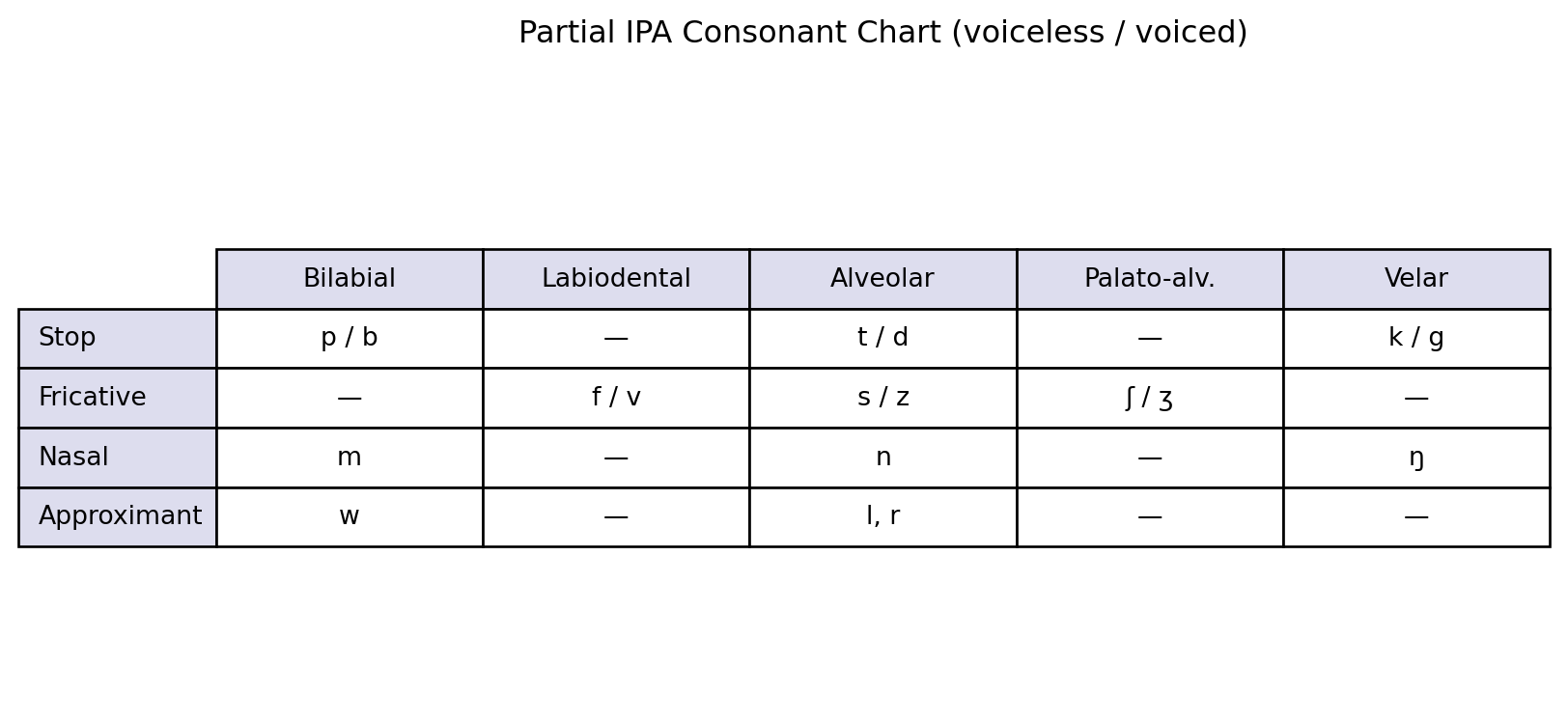
The IPA organizes consonants by three properties:
Place of articulation: where in the mouth the obstruction occurs. Bilabial (both lips): p, b, m. Labiodental (lip + teeth): f, v. Alveolar (tongue + tooth ridge): t, d, n, s, z, l, r. Velar (tongue + soft palate): k, g, ŋ.
Manner of articulation: how the airstream is obstructed. Stops (complete closure): p, b, t, d, k, g. Fricatives (turbulent flow): f, v, s, z, ʃ, ʒ. Nasals (air through nose): m, n, ŋ. Approximants (minimal obstruction): l, r, w, j.
Voicing: whether the vocal folds are vibrating. Voiced: b, d, g, v, z. Voiceless: p, t, k, f, s.
Vowels are organized differently: by the position of the tongue (front, central, back) and the height of the jaw (high, mid, low), plus lip rounding. The vowel i (as in machine) is high front unrounded. The vowel u (as in food) is high back rounded. The vowel a (as in father) is low central unrounded.
4.3 The IPA’s Origin Story
The IPA was not invented by a committee of professional linguists, which may explain why it works. It was created by Paul Passy, a French phonetician, in 1886, with the explicit goal of producing a practical tool for language teachers who needed to write down the sounds of foreign languages without ambiguity. The first version covered French, English, and German; subsequent revisions expanded it to cover the phonemic inventories of languages around the world, including the click consonants of Southern African languages (represented by symbols like ǀ and ǁ), the tonal systems of Southeast Asian languages, and the complex vowel systems of Caucasian languages.
The discipline this imposed was genuinely liberating. Before the IPA, a German writing down the sounds of Zulu would use German spelling conventions; an Englishman would use English ones; a Frenchman, French ones. The same sound would appear in a dozen incompatible orthographies across different researchers’ fieldnotes, making comparison impossible. The IPA gave everyone the same notation and the same categories.
For computational work, the IPA has a crucial additional virtue: it maps cleanly to Unicode. Every IPA symbol has a unique Unicode code point, which means that IPA-transcribed data can be stored, compared, and processed by standard text-handling software without loss. The practical consequence is that a wordlist stored as IPA text is directly machine-readable, while a wordlist stored in language-specific orthographies requires a separate transliteration step for each language.
4.4 Phonemic Transcription vs. Phonetic Transcription
There is an important distinction you will encounter throughout this book.
Phonemic transcription (between slashes: /word/) represents the abstract sound units of a language—the sounds that distinguish meaning. English has the phoneme /p/: it distinguishes pat from bat, pin from bin.
Phonetic transcription (between brackets: [word]) represents the actual physical sounds as produced in a specific context. The English /p/ in pin is actually [pʰ] (aspirated—followed by a puff of air); the /p/ in spin is [p] (unaspirated). Both are the “same” phoneme to an English speaker, but they are physically different sounds.
For etymology, phonemic transcription is usually sufficient. We care about which sounds distinguish words, not the fine-grained acoustic detail.
4.5 Phonemes as Feature Vectors
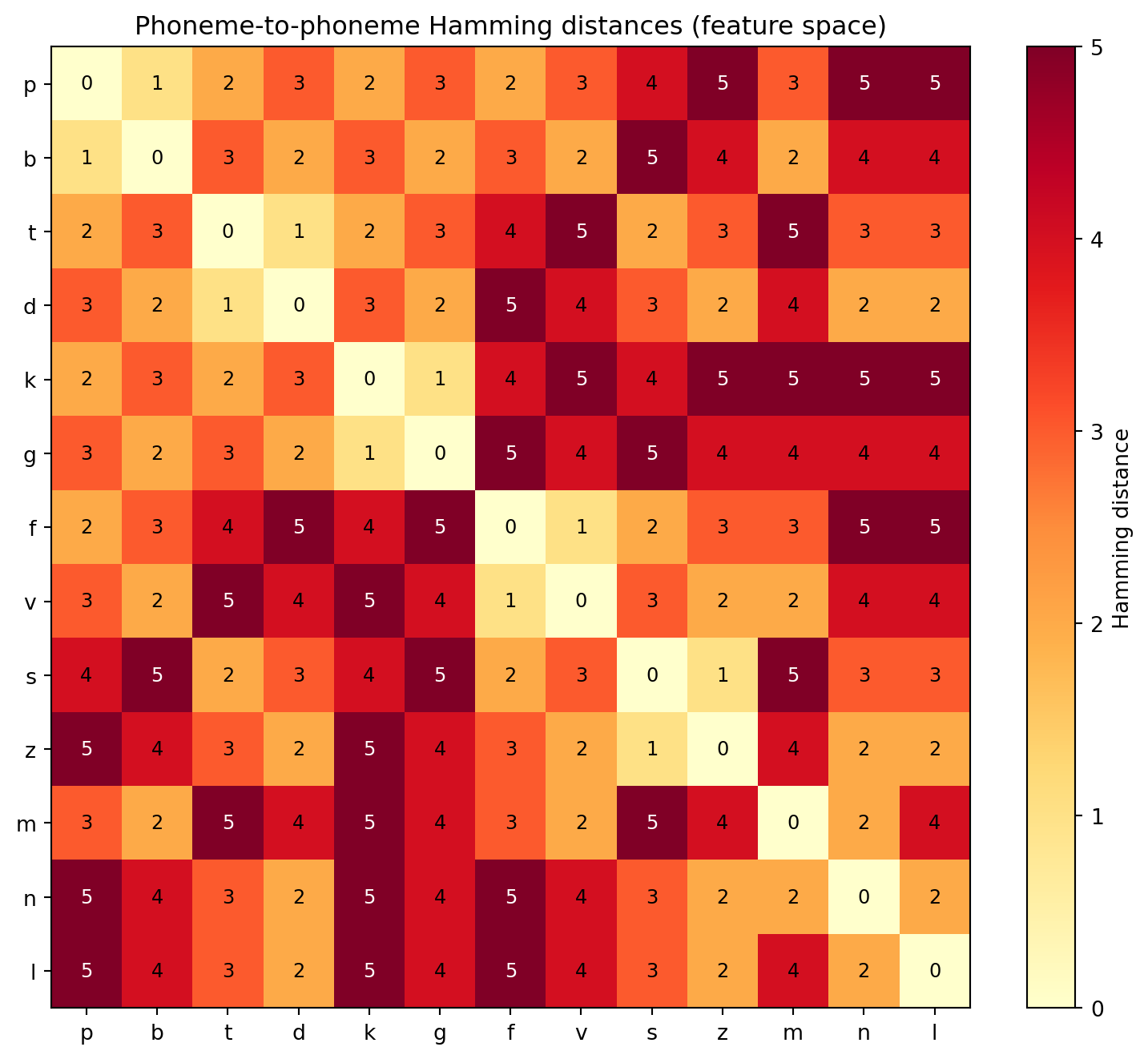
Here is the connection to data science: if every phoneme can be described by a set of binary features (voiced/voiceless, stop/fricative/nasal, bilabial/alveolar/velar…), then every phoneme can be represented as a vector of zeros and ones.
| Feature | voiced | stop | fricative | nasal | approx | bilabial | alveolar | velar |
|---|---|---|---|---|---|---|---|---|
| Phoneme | ||||||||
| p | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| b | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| t | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| d | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| k | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| g | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| f | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| v | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| s | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| z | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| m | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| n | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| l | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
Why does this matter? Because now we can compute the distance between phonemes. The distance between /p/ and /b/ is 1 (they differ only in voicing). The distance between /p/ and /s/ is 3 (they differ in voicing, stop vs. fricative, and bilabial vs. alveolar). Sounds that are close in feature space are more likely to be confused or to shift into each other over time—which is exactly what we need when we build alignment algorithms in Chapter 4.
4.6 What a Phoneme Actually Is
The concept of a phoneme is subtler than it first appears, and worth thinking through carefully because it shapes every subsequent analysis in this book.
A phoneme is not a physical sound. It is a mental category—the abstract unit that speakers of a language use to distinguish words from each other. The English phoneme /p/ covers a range of physically different sounds: the aspirated [pʰ] in pin, the unaspirated [p] in spin, and the unreleased [p̚] at the end of tip. A native English speaker perceives all three as “the same sound” because in English they never distinguish different words. In Thai, by contrast, aspirated [pʰ] and unaspirated [p] do distinguish different words—they are different phonemes. The same physical distinction that English speakers treat as irrelevant, Thai speakers must track.
This matters for our computational work in two ways. First, when we segment a word into phonemes for alignment, we need to use the phonemic distinctions of the language being analyzed—not an external standard. Second, when we compute distances between phonemes for alignment algorithms, we should use a feature system that reflects what distinctions are linguistically meaningful, not just what is physically measureable. A pitch difference of 50 Hz might or might not be phonemically significant depending on the language. Our feature vectors should encode meaningful distinctions, not raw acoustic measurements.
The feature-based approach—representing each phoneme as a vector of binary articulatory features—is the right engineering decision here, and the reason will become clearer in Chapter 4: phonetically similar sounds are geometrically close in feature space, which means that substituting one similar sound for another in an alignment costs less than substituting a dissimilar one. This is linguistically correct behavior.
4.7 The CLDF Standard
Linguistics has a proliferation-of-formats problem. Every research group has historically encoded their wordlists in a slightly different way: different column names, different transcription conventions, different handling of missing data. This makes reuse difficult.
The Cross-Linguistic Data Formats (CLDF) standard, developed in the 2010s by Johann-Mattis List and collaborators, is an attempt to fix this. A CLDF wordlist is a set of CSV files with standardized column names, machine-readable metadata, and links between tables. The key tables are:
languages.csv: one row per language (ID, name, Glottocode, coordinates)parameters.csv: one row per concept (ID, Concepticon concept reference)forms.csv: one row per form (language ID, parameter ID, transcription, segments)cognates.csv: one row per cognate judgment (form ID, cognate set ID)
You do not need to work with CLDF directly to use this book—we will often work with simplified CSV files—but you will encounter it in the wild and knowing its structure saves confusion.
Language_ID Parameter_ID Form N_segments
0 spa father padre 5
1 fra father père 3
2 ita father padre 5
3 por father pai 3
4 spa night noche 4
5 fra night nuit 3
6 ita night notte 5
7 por night noite 5The Segments column is the key: it contains the IPA transcription with spaces between phonemes, so that splitting on whitespace gives you a list of phonemes directly. This is the standard segmentation format in CLDF. Notice that French père has three segments (p-ɛ-r) while Italian notte has four (n-o-t-t-e, where the geminate tt counts as two segments). These length differences are exactly what a sequence alignment algorithm must handle.
4.8 Segmentation
Segmenting a transcribed word into phonemes sounds trivial—just split on spaces—but the issue of multigraphs complicates things. In IPA, some sounds are represented by two characters: tʃ (the sound in church), dʒ (the sound in judge), ts (the sound in cats). If you split character-by-character rather than phoneme-by-phoneme, you get the wrong segmentation.
LingPy, the Python library we will use extensively in Chapter 4, includes a segmentation function that handles these cases:
['n', 'a', 'tʃ']The function knows that tʃ is a single phoneme and should not be split. This is not trivial knowledge—it is embedded in the library’s symbol table, derived from the IPA standard.
4.9 Data Quality Issues
Real linguistic datasets are messy. Here are the issues you will most commonly encounter:
Inconsistent transcription. Different scholars use slightly different conventions. Some use j for the palatal approximant (English yes); others use y. Some mark stress; others do not. This must be normalized before any automated analysis.
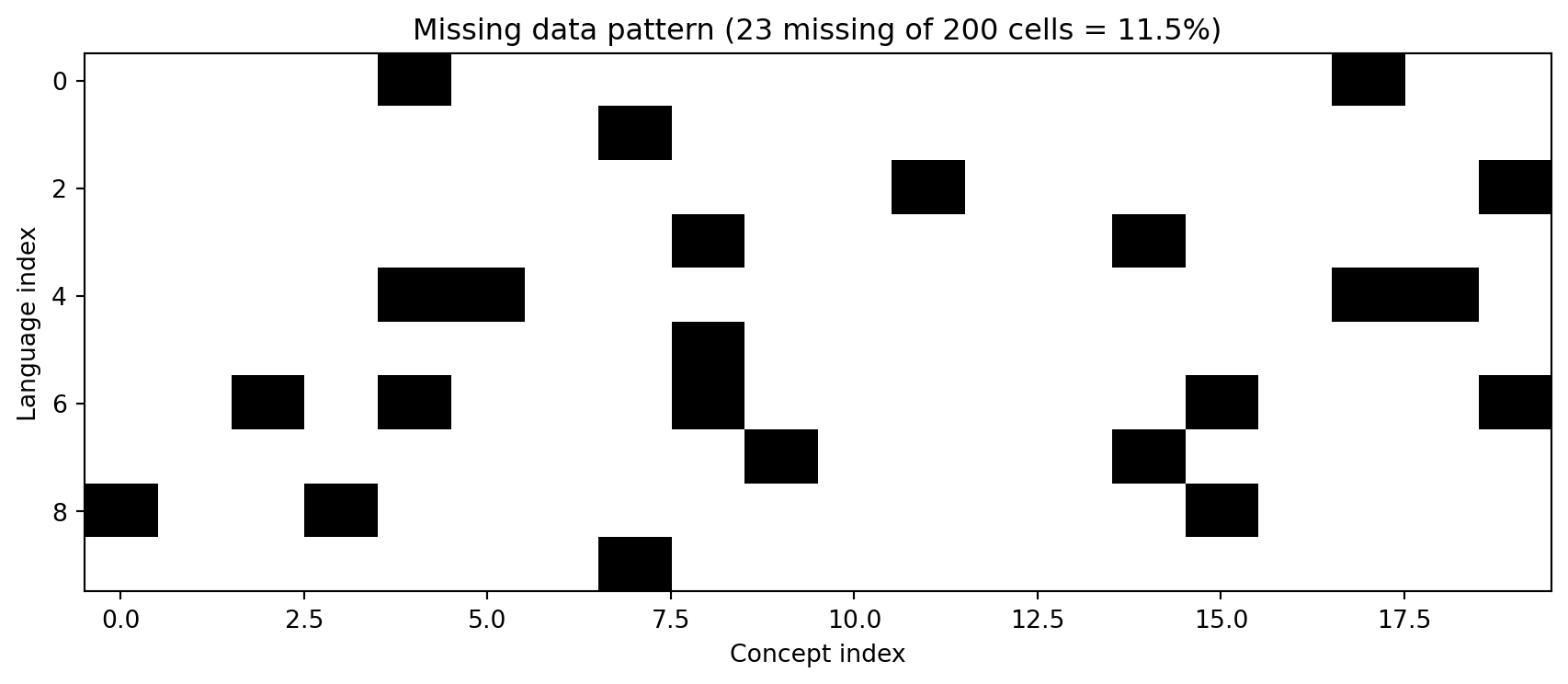
Missing data. Not all languages have words for all concepts. If the concept does not exist in the culture, there is no word. CLDF uses explicit null markers; ad hoc datasets often leave cells blank, use “N/A,” or use “—”, all of which must be handled separately.
Loans mixed with inherited vocabulary. A wordlist for English will contain borrowed words from French, Latin, Old Norse, and Greek alongside the inherited Germanic vocabulary. If you run a cognate detector without filtering loanwords, you will find false cognates everywhere.
Dialectal variation. The “Spanish” word for a concept may vary substantially between Madrid, Mexico City, and Buenos Aires. Which dialect is recorded matters—and is often not documented.
4.10 Building Your Own Feature Matrix
To close this chapter with a concrete object you can use in later chapters, let us build a complete feature matrix for a small phoneme inventory:
Feature-based phoneme distance matrix:
p b t d k g f v s z m n l
p 0 1 2 3 2 3 2 3 4 5 3 5 5
b 1 0 3 2 3 2 3 2 5 4 2 4 4
t 2 3 0 1 2 3 4 5 2 3 5 3 3
d 3 2 1 0 3 2 5 4 3 2 4 2 2
k 2 3 2 3 0 1 4 5 4 5 5 5 5
g 3 2 3 2 1 0 5 4 5 4 4 4 4
f 2 3 4 5 4 5 0 1 2 3 3 5 5
v 3 2 5 4 5 4 1 0 3 2 2 4 4
s 4 5 2 3 4 5 2 3 0 1 5 3 3
z 5 4 3 2 5 4 3 2 1 0 4 2 2
m 3 2 5 4 5 4 3 2 5 4 0 2 4
n 5 4 3 2 5 4 5 4 3 2 2 0 2
l 5 4 3 2 5 4 5 4 3 2 4 2 0This matrix will serve directly as the cost matrix in our alignment algorithm in Chapter 4: substituting one similar phoneme for another (e.g., p for b, distance 1) costs less than substituting a dissimilar one (e.g., p for n, distance 3). The cost matrix is what allows alignment to prefer linguistically plausible correspondences over linguistically arbitrary ones.
4.11 Summary
Orthography is a poor representation of sound; IPA provides a one-to-one mapping that computational methods require. Phonemes are usefully described by articulatory features—voicing, place, manner—which can be encoded as binary feature vectors. Those vectors allow the computation of phoneme-to-phoneme distances, which will power the alignment algorithms of Chapter 4. The CLDF standard provides a consistent format for multilingual wordlists. Real datasets have messy realities: inconsistent transcription, missing data, unlabeled loanwords, and dialectal variation. Cleaning and normalizing data is always the first step.
4.12 Further Reading
- Ladefoged, P., & Johnson, K. (2014). A Course in Phonetics (7th ed.). Cengage. The standard textbook.
- List, J.-M., Greenhill, S. J., Anderson, C., Mayer, T., Tresoldi, T., & Forkel, R. (2018). CLDF: Encoding Cross-Linguistic Data in a Machine-Readable Way. Language Documentation & Conservation.
- Moran, S., & Cysouw, M. (2018). The Unicode Cookbook for Linguists. Language Science Press. Free PDF; excellent on the practical problems of linguistic data encoding.
- IPA chart: https://www.internationalphoneticassociation.org/IPAcharts