13 Etymology as Knowledge Graphs
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Design a graph schema for etymological relationships (nodes, edges, types)
- Build and query an etymology graph using NetworkX
- Find patterns: “which roots have the most descendants?”, “how did this root spread?”
- Visualize language relationship networks and cognate clusters
- Identify communities in the etymology graph
- Describe the architecture of large-scale etymology databases (BabelNet, Wiktionary)
13.1 The Web Behind the Words
Every word is a node. Every etymological relationship is an edge. The connections between them—descent, borrowing, derivation, cognacy—form a graph whose topology reflects ten thousand years of human migration, conquest, trade, and contact.
This is not a new observation. Etymological dictionaries have always been implicit graph structures: every entry points to the forms it derives from, and those entries point to theirs. What has changed is that we now have both the computational tools to represent these relationships explicitly—with typed edges, attributes, and queryable structure—and the data to populate such a graph at scale.
Wiktionary’s English edition alone contains over a million etymological links. BabelNet connects 500 languages through a semantic network that includes etymological relations. The EtymWordNet project has extracted etymological graphs from Wiktionary data in machine-readable format. These are not research prototypes; they are live, queryable resources.
The graph representation makes visible things that prose cannot show: the family trees of roots, the paths of borrowing across languages, the clusters of words that share a common ancestor but have traveled very different routes to arrive in modern English.
13.2 Graph Schema for Etymology
A minimal etymology graph needs:
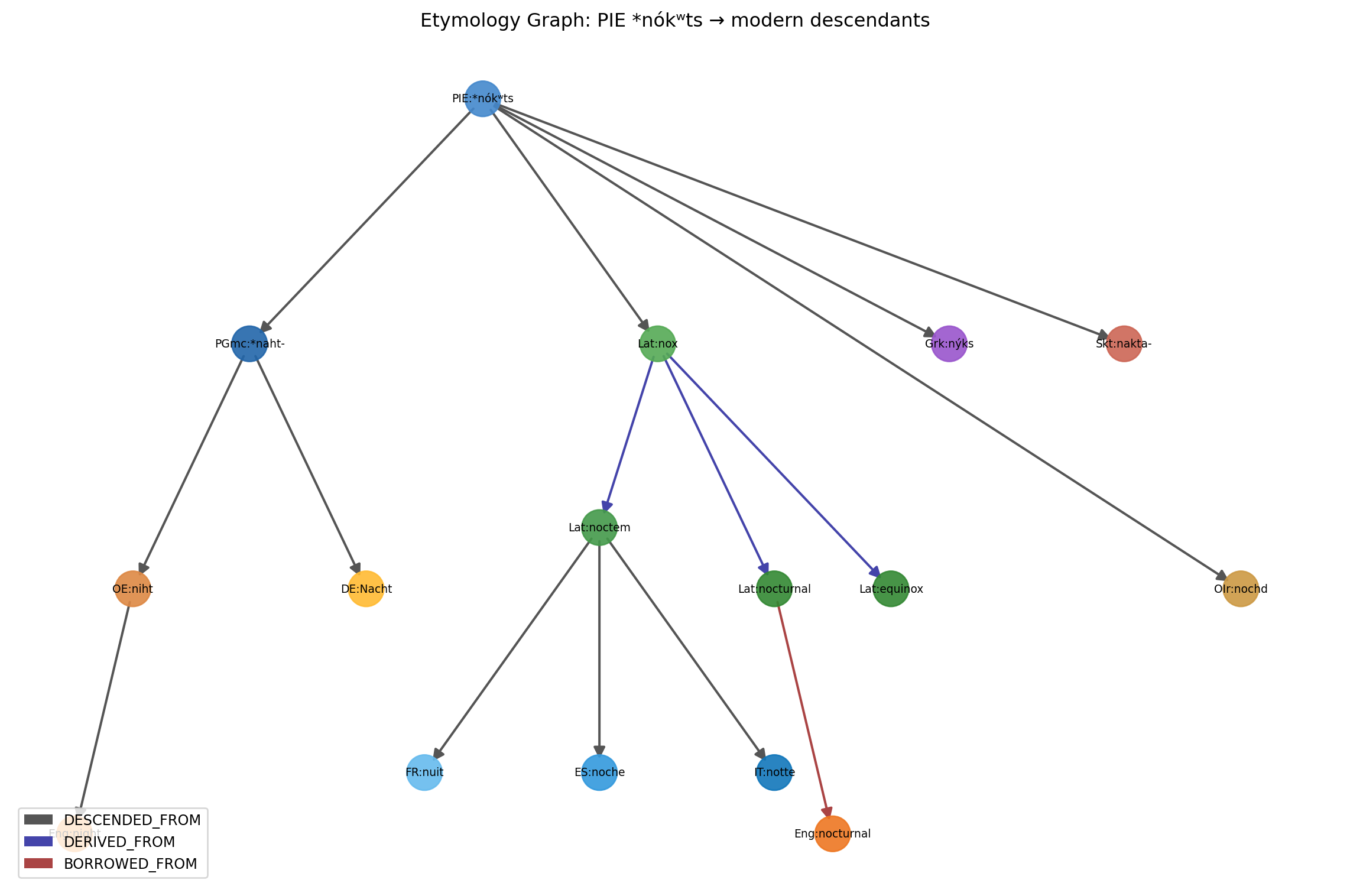
Node types: - Word: a specific form in a specific language (e.g., English “night”, Latin “nox”) - Root: a reconstructed proto-form (e.g., PIE *nókʷts) - Language: a language node (optional, for grouping)
Edge types: - DESCENDED_FROM: a word descended from a proto-form or ancestor word - COGNATE_WITH: two words sharing a common ancestor (can be derived from DESCENDED_FROM) - BORROWED_FROM: a loanword relationship - DERIVED_FROM: morphological derivation (prefixation, suffixation) within a language - COMPOUND_OF: compound word decomposition
Graph: 16 nodes, 15 edges
Descendants of PIE:*nókʷts:
Eng:nocturnal
OIr:nochd
PGmc:*naht-
Lat:noctem
ES:noche
OE:niht
Lat:equinox
Eng:night
DE:Nacht
Skt:nakta-
IT:notte
FR:nuit
Grk:nýks
Lat:nocturnal
Lat:nox13.3 Why Graphs Beat Tables for Etymology
A relational database of etymological data—the obvious first choice for anyone with a data engineering background—runs into structural problems quickly.
Consider how you would store the relationship between Latin nox and English night. In a table, you might have a row for Latin nox and a row for English night, connected by a foreign key indicating “descended from the same proto-form.” But what if you also want to store that Latin nox is the source of the English borrowings nocturnal, equinox, and noctule (a species of bat)? And that noctule was borrowed in the eighteenth century while equinox was borrowed in the fourteenth? And that equinox is itself a compound of nox and a form of aequus? And that aequus has its own descendants?
A table can store all of this—but querying it requires recursive joins, which are cumbersome in standard SQL and catastrophically slow on large datasets. The query “find all English words that, through any chain of derivation or descent, trace back to Proto-Indo-European root *nókʷts” is a transitive closure query—the exact operation that relational databases are worst at and that graph databases are optimized for.
The graph model is the natural fit because etymology is a graph. Words are not independent items in a list; they are nodes in a network of relationships, and the interesting questions about etymology are almost all about paths through that network. Which words share a common ancestor? How many steps separates two apparently unrelated words? Which roots have the most descendants? These are graph traversal questions, not table lookup questions, and the right data structure for graph traversal questions is a graph.
13.4 Graph Queries
The power of graph representation is queryability. Here are canonical queries for etymological research:
English descendants of PIE *nókʷts: ['Eng:nocturnal', 'Eng:night']
No directed path found.
Top nodes by number of direct descendants:
PIE:*nókʷts: 5 direct descendants
Lat:nox: 3 direct descendants
Lat:noctem: 3 direct descendants
PGmc:*naht-: 2 direct descendants
OE:niht: 1 direct descendants
Cognate pairs in graph: 91
Sample cognate pairs:
Lat:nocturnal ↔ Lat:noctem
Lat:nox ↔ FR:nuit
Lat:nocturnal ↔ FR:nuit
Lat:nox ↔ Grk:nýks
Skt:nakta- ↔ ES:noche13.5 Scaling Up: Wiktionary as a Graph
The same schema applies at scale. Wiktionary’s English edition has been parsed into machine-readable format by the EtymWordNet and EtymoLinks projects. A full Wiktionary etymology graph contains:
- ~1.2 million word nodes
- ~50 languages with substantial coverage
- ~3 million etymological edges (descent, borrowing, derivation)
At this scale, NetworkX becomes slow (it is not designed for graphs of millions of nodes). Production systems use Neo4j (a dedicated graph database) or Apache Spark GraphX for distributed processing.
Query languages change: instead of Python graph traversal, you write Cypher queries (Neo4j’s SQL-like graph query language):
# Find all English words with Latin roots (in Neo4j Cypher, not executable here)
# MATCH path = (w:Word {language:'English'})-[:DESCENDED_FROM*]->(r:Word {language:'Latin'})
# RETURN w.form, r.form, length(path) as hops
# ORDER BY hops ASC13.6 Community Detection: Natural Clusters in Etymology
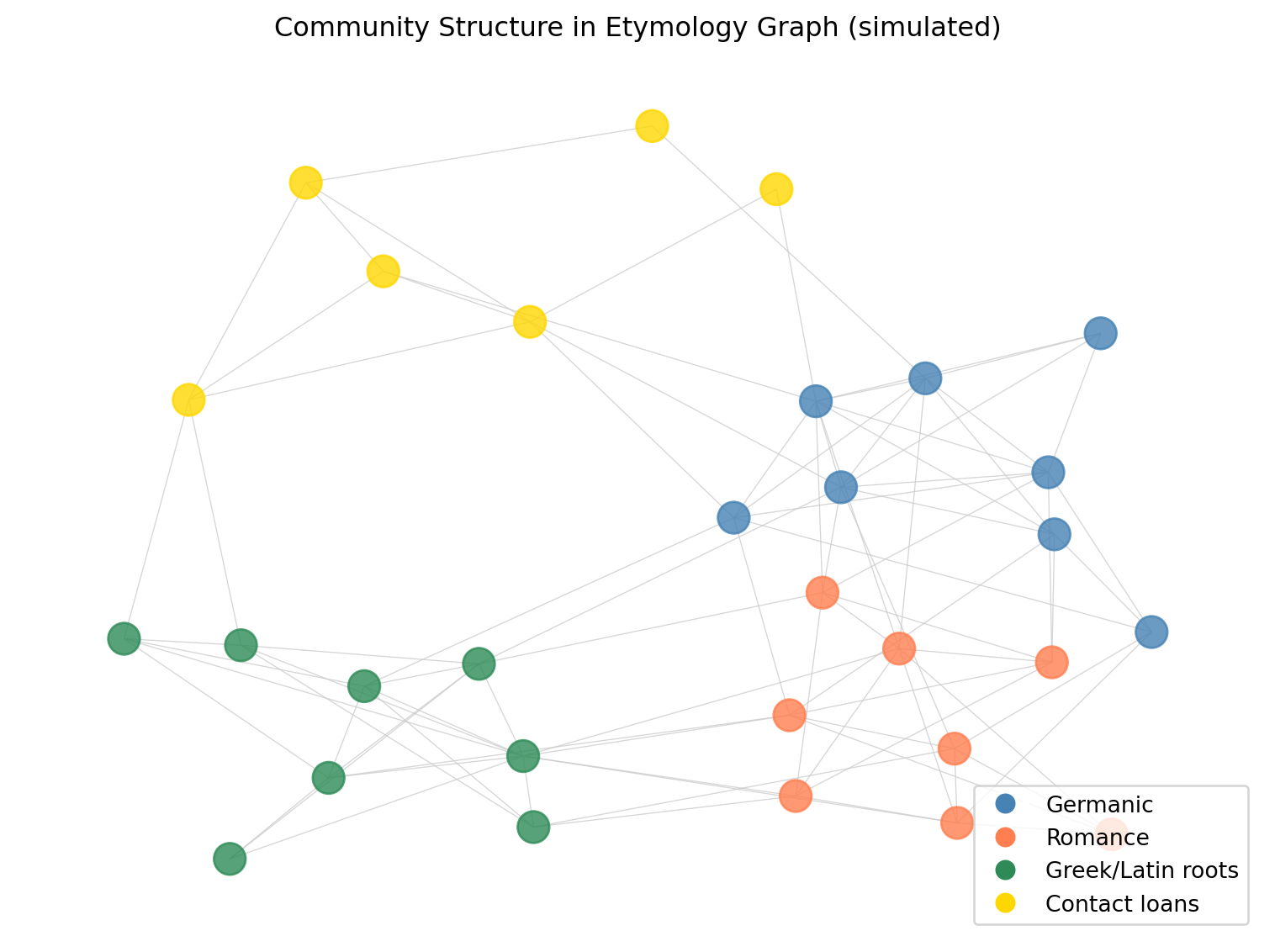
Etymology graphs have community structure: clusters of words that are more densely connected to each other than to the rest of the graph. These communities often correspond to meaningful linguistic groupings.
13.7 Summary
Etymology graphs represent words as nodes and historical relationships (descent, borrowing, derivation) as typed, directed edges. This representation enables queries that are impossible in prose: finding all descendants of a proto-root, computing the shortest path between two words through their common ancestor, identifying the most productive roots (by number of descendants), and detecting cognate pairs automatically from transitive descent relationships. At the scale of a single language family, NetworkX provides all necessary tools. At Wiktionary scale (millions of nodes), graph databases like Neo4j are required. Community detection algorithms applied to etymology graphs recover linguistically meaningful clusters that correspond to language families and borrowing strata. The structured etymology dataset produced in Chapter 10 feeds directly into the graph construction pipeline described here.
13.8 Further Reading
- Navigli, R., & Ponzetto, S. P. (2012). BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. Artificial Intelligence.
- Tahmasebi, N., et al. (2018). On the uses of word sense change for research in the digital humanities. Historical Methods.
- EtymWordNet: https://etym.org — Browse etymological graphs derived from Wiktionary.
- Kirov, C., et al. (2016). Very-large scale parsing and normalization of Wiktionary morphological paradigms. LREC 2016.