5 Sequence Alignment & Phonetic Distance
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Implement the Levenshtein edit distance algorithm from scratch
- Explain why basic edit distance is insufficient for linguistic data
- Construct a phonetically-weighted substitution cost matrix
- Implement the Needleman-Wunsch global alignment algorithm
- Align word pairs and interpret the result linguistically
- Evaluate alignment quality against gold-standard datasets
5.1 The Biologist’s Gift
In 1970, a computational biologist named Saul Needleman and a computer scientist named Christian Wunsch published an algorithm for aligning biological sequences—the DNA and protein sequences whose comparison was becoming central to molecular biology. Their algorithm found the globally optimal alignment of two sequences, given a scoring scheme that rewarded matches and penalized mismatches and gaps.
Fifteen years later, when computational linguists started thinking seriously about the problem of automatically aligning cognate word forms, they reached for the same tool. The analogy was not superficial. A sequence of phonemes is structurally identical to a sequence of nucleotides: a finite string of symbols drawn from a defined alphabet, where the order matters and where certain substitutions are more likely than others.
The gift from biology was not just the algorithm. It was the conceptual framing: aligning sequences is a problem with a mathematically well-defined optimal solution. You do not have to guess; you can compute.
5.2 Edit Distance: The Starting Point
The Levenshtein edit distance between two strings is the minimum number of single-character operations—insertions, deletions, substitutions—needed to transform one string into the other. It is the foundation of all sequence comparison.
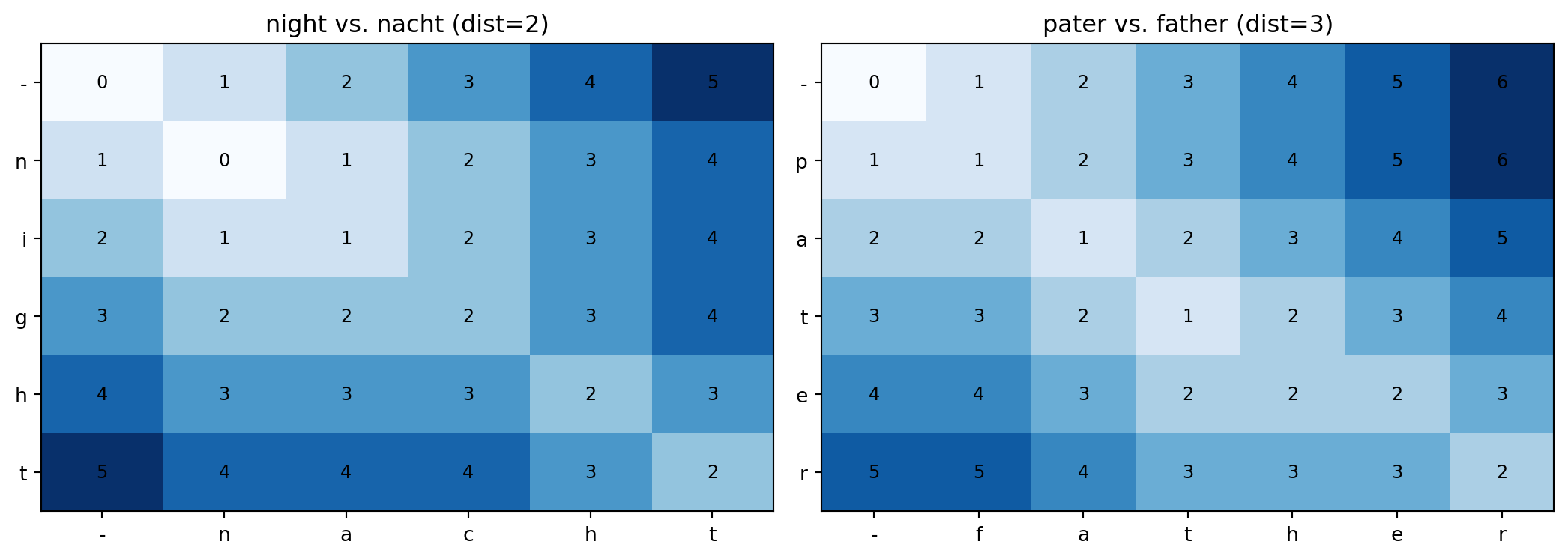
Edit distance('night', 'nacht') = 2.0
Edit distance('pater', 'father') = 2.0night vs. nacht: distance 2 (the vowel [aɪ]→[a] and the final t→t match, but the medial consonant cluster differs). pater vs. father: distance 3 (the p→f shift, the vowel, and the t→th shift). These distances are correct as string distances, but they do not capture the linguistic significance of the differences. The p→f correspondence is a known, regular sound change (Grimm’s Law); the algorithm treats it as arbitrary.
5.3 Why Dynamic Programming Works
The edit distance algorithm is an instance of dynamic programming—a technique for solving problems by breaking them into smaller subproblems and storing the results. It is worth understanding why this works, because the same structure appears in nearly every alignment algorithm in the book.
The key insight is optimal substructure: the optimal alignment of two sequences must contain the optimal alignment of every prefix of those sequences. If the best alignment of night and nacht uses a particular path through the DP table, every initial segment of that path must also be optimal for the corresponding prefixes. If it were not—if some sub-alignment were suboptimal—you could replace it with a better one and improve the overall alignment, contradicting the assumption that you had found the optimum.
This means you can build the optimal alignment for the full sequences by computing optimal alignments for progressively longer prefixes, reusing previously computed results at each step. The \(O(mn)\) time complexity is the cost of filling a table of \(m \times n\) cells, each requiring \(O(1)\) work. Without dynamic programming, a naive search over all possible alignments would take exponential time—\(O(3^{\max(m,n)})\)—because there are exponentially many ways to insert gaps.
For etymology, this matters practically: aligned cognate pairs from a language family of 50 languages and 200 concepts require aligning \(\binom{50}{2} \times 200 = 245,000\) word pairs. At \(O(mn)\) with average word length 6, that is roughly 8.8 million cell operations—trivial on modern hardware. Exponential time would make the computation impossible.
5.4 The Problem with Orthographic Edit Distance
Plain edit distance has three problems for etymology.
First, it operates on orthography, not phonology. English knight has seven letters but four phonemes: /n/, /aɪ/, /t/. Comparing strings of letters introduces silent letters, digraphs (th, ch, ng), and other orthographic artifacts that have nothing to do with sound.
Second, all substitutions cost the same. Substituting p for b costs the same as substituting p for s, even though p→b is a trivial voicing change and p→s requires changing both place and manner of articulation. A linguistically aware algorithm should make similar sounds cheaper to substitute.
Third, gap placement is unconstrained. When a gap is inserted (to handle words of different length), all positions are equally valid. But in linguistics, certain positions are more likely to gain or lose sounds—word-final position is especially prone to loss, for instance.
The solution to all three is phonetically-weighted alignment.
5.5 Weighted Alignment with a Cost Matrix
We replace the uniform substitution cost with a matrix \(C\) where \(C_{ij}\) is the cost of substituting phoneme \(i\) for phoneme \(j\). We build this matrix from the feature vectors of Chapter 3.
Selected substitution costs (0=identical, 1=maximally different):
p ↔ b: 0.125
p ↔ f: 0.250
p ↔ s: 0.500
p ↔ n: 0.625
t ↔ d: 0.125
t ↔ n: 0.375Now /p/↔︎/b/ costs 0.125 (one feature difference out of eight), while /p/↔︎/n/ costs 0.5 (four feature differences). The alignment algorithm will prefer p→b over p→n because it is phonetically cheaper.
5.6 The Needleman-Wunsch Algorithm
The Needleman-Wunsch algorithm is a global alignment algorithm: it aligns the full sequences from end to end, including gap characters where needed. The DP recurrence is:
\[ F(i, j) = \max \begin{cases} F(i-1, j-1) + s(x_i, y_j) & \text{(substitution or match)} \\ F(i-1, j) - g & \text{(gap in } y \text{)} \\ F(i, j-1) - g & \text{(gap in } x \text{)} \end{cases} \tag{5.1}\]
where \(s(x_i, y_j)\) is the score for aligning phoneme \(x_i\) with phoneme \(y_j\) (positive for similar sounds, negative for dissimilar), and \(g\) is the gap penalty.
For etymology, we typically convert this to a cost minimization form: alignment cost rather than alignment score.
night [naIt] vs. Nacht [naxt]:
EN: n a I t
DE: n a x t
Alignment cost: 0.500
pater [pater] vs. father [faðer]:
LA: p a t e r
EN: f a ð e r
Alignment cost: 0.7505.7 Visualizing Alignments
A well-aligned word pair reveals the sound correspondences at a glance:

5.8 Evaluating Alignments
How do you know whether an alignment is good? Two standard metrics are used in the literature.
Sum-of-pairs score: for each column of the alignment, compute the cost of the pair in that column; sum across columns. Lower is better.
B-cubed precision and recall: computed against a gold-standard alignment provided by expert linguists. Precision measures how many of the automatically proposed correspondences are correct; recall measures how many of the gold-standard correspondences the algorithm found. F1 is the harmonic mean.
The ASJP (Automated Similarity Judgments Program) database and the EDICTOR tool provide gold-standard alignments for several language families that serve as benchmarks for algorithm evaluation.
Alignment accuracy (night/Nacht): 100%5.9 Gap Penalties and Linguistic Reality
One parameter in alignment algorithms that deserves more attention than it typically gets is the gap penalty—the cost of inserting a gap (representing an insertion or deletion in the evolutionary history of the word).
In the uniform-cost version of edit distance, a gap costs the same regardless of where it falls. This is linguistically unrealistic. Word-final position is far more susceptible to sound loss than word-internal position—the process called apocope (loss of final sounds) is one of the most common types of sound change. Latin noctem became French nuit partly through loss of the final -m and then the -ct- cluster. Latin filium became French fils, losing multiple sounds. If our alignment algorithm charged the same penalty for a gap in word-final position as for a gap in word-initial position, it would systematically undervalue alignments that involve word-final loss.
More sophisticated alignment algorithms use affine gap penalties: gap opening (the cost of starting a new run of gaps) is penalized more heavily than gap extension (the cost of continuing an existing gap). This reflects the empirical observation that a single deletion event often removes several adjacent sounds rather than isolated ones. A word that lost its final syllable lost multiple sounds in a single event; charging separately for each is historically misleading.
LingPy’s SCA (Sound Class Alignment) algorithm, the standard in the field, uses a gap penalty scheme tuned to the observed statistics of sound change across a large number of language families. The penalty values are not arbitrary; they are estimated from the empirical distribution of gap positions in gold-standard alignments. This is, in microcosm, the right approach to parameter selection in computational linguistics: let the data constrain the model rather than setting parameters by intuition.
5.10 Summary
Sequence alignment is the algorithmic foundation of computational etymology. Levenshtein edit distance provides a baseline but treats all substitutions equally and operates on orthography rather than phonemes. Phonetically-weighted alignment—using a cost matrix derived from articulatory feature distances—produces linguistically meaningful alignments that prefer regular sound changes over arbitrary ones. The Needleman-Wunsch algorithm finds the globally optimal alignment under any cost matrix in \(O(mn)\) time. Alignment quality is evaluated against gold-standard datasets using B-cubed precision and recall. These aligned pairs are the raw material that cognate detection (Chapter 5) and phylogenetic inference (Chapter 6) consume.
5.11 Further Reading
- Needleman, S. B., & Wunsch, C. D. (1970). A general method applicable to the search for similarities in the amino acid sequence of two proteins. Journal of Molecular Biology.
- List, J.-M. (2012). LexStat: Automatic detection of cognates in multilingual wordlists. Proceedings of the EACL Workshop on Language Evolution and Computational Linguistics.
- Jäger, G. (2019). Computational historical linguistics. Theoretical Linguistics.
- Kondrak, G. (2000). A new algorithm for the alignment of phonetic sequences. NAACL 2000 Proceedings.