| Spanish | Portuguese | French | Italian | Romanian | Latin | |
|---|---|---|---|---|---|---|
| 0 | noche | noite | nuit | notte | noapte | noctem |
| 1 | agua | água | eau | acqua | apă | aquam |
| 2 | padre | pai | père | padre | tată | patrem |
| 3 | mano | mão | main | mano | mână | manum |
| 4 | nuevo | novo | nouveau | nuovo | nou | novum |
| 5 | luna | lua | lune | luna | lună | lunam |
| 6 | vida | vida | vie | vita | viață | vitam |
| 7 | nombre | nome | nom | nome | nume | nomen |
9 Proto-Language Reconstruction
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Frame proto-form reconstruction as a sequence-to-sequence prediction problem
- Explain the encoder-decoder architecture in plain language
- Describe what attention mechanisms do and why they matter for this task
- Interpret the output of a reconstruction model and its uncertainty
- Understand the Ciobanu-Dinu benchmark for Romance proto-reconstruction
- Recognize the limits of neural reconstruction and when expert judgment remains essential
9.1 The Reversed Arrow of Time
The standard way of thinking about language change points forward in time: Latin noctem becomes Spanish noche. The sound changes, the vowels drift, the case endings drop. Change flows in one direction.
Proto-language reconstruction reverses the arrow. Given Spanish noche, French nuit, Italian notte, and Portuguese noite, can we recover Latin noctem—or, more generally, the proto-form that preceded all of them?
Traditional linguists do this by hand: they compare the forms, identify the correspondences, and apply the sound laws in reverse. It works beautifully when the sound laws are known, when enough descendants have been recorded, and when the linguist has years of experience with the language family. It does not scale.
Neural sequence-to-sequence models do scale. Trained on thousands of examples of (modern forms → proto-form), they learn the inverse sound changes implicitly, without being explicitly programmed with any rules. The results, on held-out test data, are remarkably accurate: roughly 32% of reconstructed proto-forms are letter-perfect, and over 60% are within one character substitution of the correct answer.
This is not as impressive as 99% accuracy, but it is meaningful: an automatic system is doing, at scale and in milliseconds, something that took expert linguists a career.
9.2 Framing the Problem
The formal problem is:
Given \(k\) cognate reflexes (one per descendant language), predict the proto-form from which they all descended.
This is a many-to-one sequence transduction problem. The input is a set of sequences (one per language); the output is a single sequence (the proto-form). The challenge is that the mapping is irregular: no single reflex fully determines the proto-form, and different descendants preserve different features of the ancestor.
In the Romance reconstruction benchmark introduced by Ciobanu and Dinu (2018), the task is: - Input: aligned cognates from Spanish, Portuguese, French, Italian, Romanian - Output: Latin form (accusative singular, which is the ancestral form of modern Romance nouns)
9.3 Encoder-Decoder Architecture
The dominant architecture for sequence transduction tasks is the encoder-decoder model, introduced in its modern form by Sutskever, Vinyals, and Le in 2014.
The encoder reads the input sequence and produces a fixed-size representation—a vector (or matrix) that summarizes the input’s content. The decoder then generates the output sequence, one token at a time, using the encoder’s representation.
For proto-reconstruction with multiple input languages, the encoder processes each language’s reflex separately, and the decoder attends to all of them when generating each proto-phoneme.
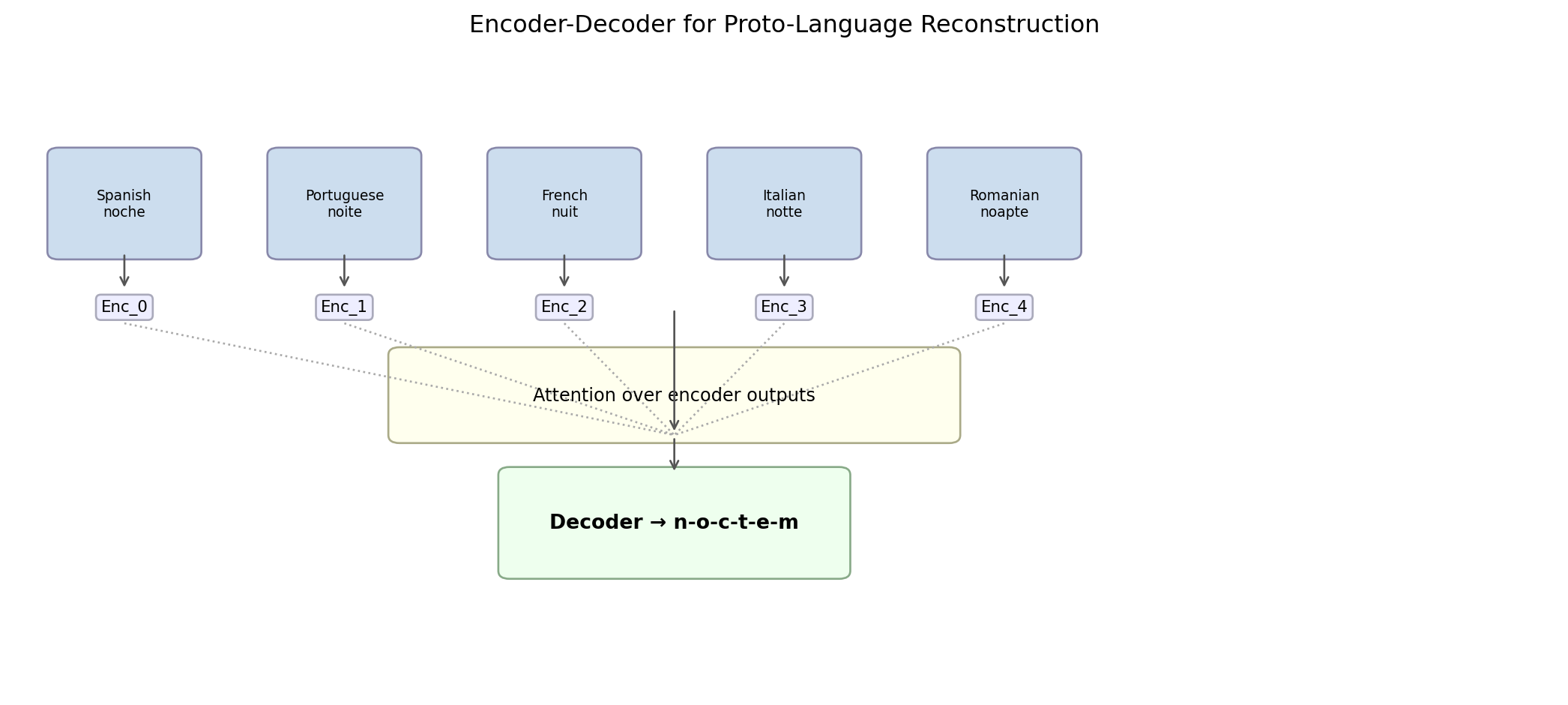
9.4 Attention: What the Decoder Looks At
The attention mechanism solves a specific problem: the decoder needs to generate noctem, but different parts of the output depend on different input languages in different ways.
When generating the initial n, the Spanish noche and Italian notte are the most informative—both start with n. When generating the ending -em, Latin morphology must be inferred from the pattern of accusative endings across all five languages. Attention allows the decoder to weight each input dynamically at each output timestep.
Formally, the attention weight for language \(i\) at output step \(t\) is:
\[ \alpha_{t,i} = \frac{\exp(e_{t,i})}{\sum_j \exp(e_{t,j})}, \quad e_{t,i} = f(\mathbf{h}^{\text{dec}}_t, \mathbf{h}^{\text{enc}}_i) \tag{9.1}\]
where \(\mathbf{h}^{\text{dec}}_t\) is the decoder state at step \(t\), \(\mathbf{h}^{\text{enc}}_i\) is the encoder output for language \(i\), and \(f\) is a compatibility function (typically a dot product or a learned linear transformation).
This is the same attention mechanism that powers modern transformers, applied to a specialized multilingual input structure.
9.5 A Rule-Based Baseline
Before implementing a neural model, it is worth building a simple rule-based baseline—both to understand the problem structure and to set a performance floor.
Input forms Reconstructed True Latin Match?
------------------------------------------------------------------------------------------
['noche', 'noite', 'nuit', 'notte', 'noapte'] noitee noctem ✗
['agua', 'água', 'eau', 'acqua', 'apă'] aguaa aquam ✗
['padre', 'pai', 'père', 'padre', 'tată'] padre patrem ✗
['nuevo', 'novo', 'nouveau', 'nuovo', 'nou'] nouvoau novum ✗The majority vote baseline does surprisingly well on some words and fails badly on others. Agua/aqua reconstructs the a-qu-a pattern from majority votes but cannot recover the Latin accusative ending -m. Padre/père cannot recover patrem because the forms have diverged so much.
These failures are informative: the neural model’s advantage comes from learning cross-position dependencies (the ending depends on the whole word pattern, not just the final position) and cross-language patterns (French regularly drops Latin endings, Spanish preserves some, Romanian preserves others).
9.6 Sound Correspondence Tables
Before a neural model can learn to reconstruct proto-forms, a human (or an alignment algorithm) must first determine which character in the modern form corresponds to which character in the Latin original. This step—establishing sound correspondences— is what the comparative method has been doing by hand for two centuries. It is also what the encoder’s attention mechanism is learning to do implicitly.
A sound correspondence table records, for a given pair of languages, which source phoneme maps to which target phoneme. For Latin-to-Spanish, the classic Grimm-like correspondences include: Latin ct → Spanish ch (noctem → noche, lactem → leche), Latin pl/cl/fl- → Spanish ll (planum → llano), and Latin final -m → Spanish zero (the accusative ending simply vanishes).
We can compute an empirical correspondence table directly from our aligned dataset.
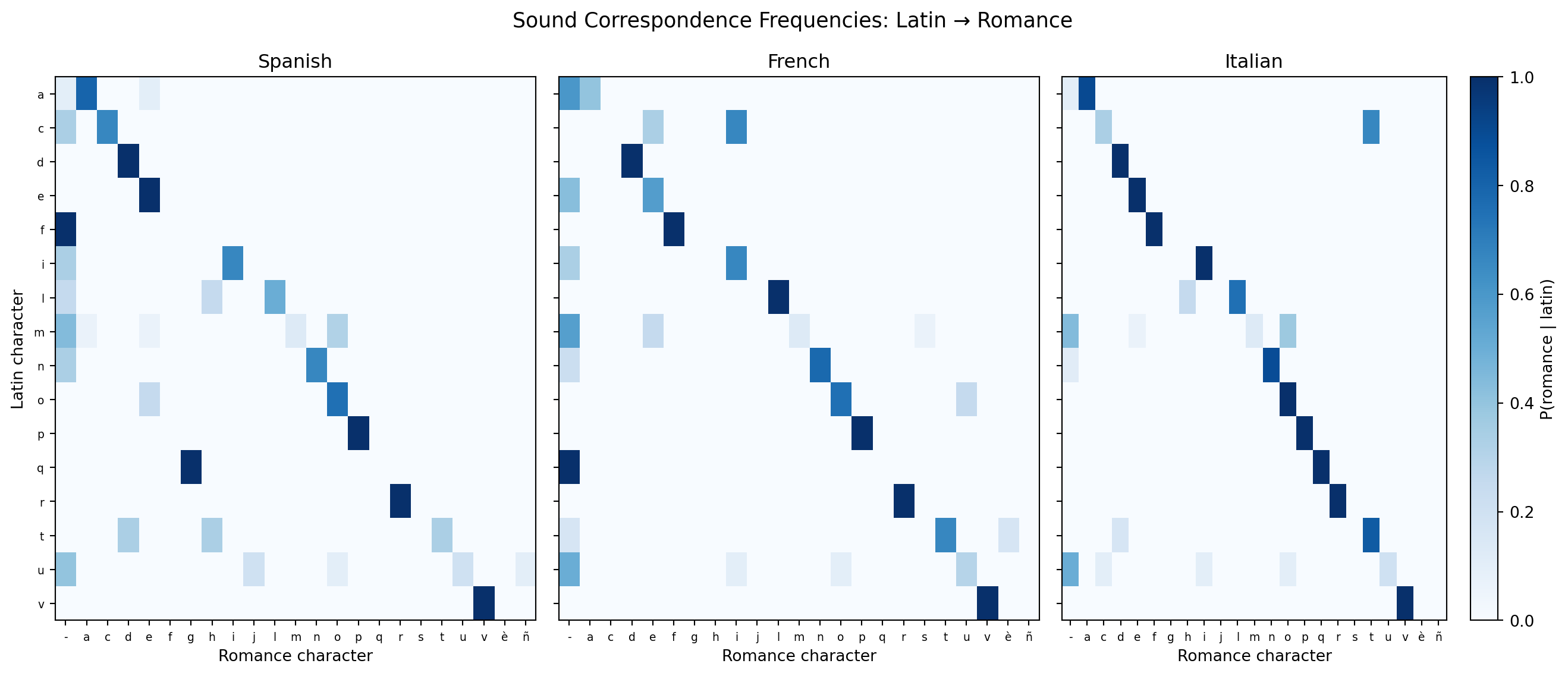
Several patterns stand out immediately. Latin c maps predominantly to itself in Italian (acqua, occhio) but spreads across ch, j, and zero in Spanish. Latin final m almost always maps to a gap (deletion), which is why the accusative ending is invisible in every modern descendant — a neural model must hallucinate it from context, not read it from any surviving reflex. French eau and nuit look nothing like Latin aquam and noctem because the vowel chain-shifts of Old French compressed what had been three or four distinct Latin vowels into a narrower modern inventory.
9.7 Aligning Cognates Before Reconstruction
The neural model treats reconstruction as sequence-to-sequence transduction, but it first needs its input cognates to be aligned — each position in the source sequences corresponding to the same ancestral sound. Without alignment, the encoder cannot learn which characters are cognate across languages.
We can visualize what alignment looks like for a single word before feeding it to any model.

The alignment grid makes visible what a linguist means when they say that French nuit and Latin noctem are cognate. The n matches; the o became ui (a chain shift in Old French); the ct cluster became silent and then vanished; the final em dropped entirely. Every step is documented in the historical record. The alignment represents all of it in a form the encoder can read.
9.8 Simulating Attention: What Each Language Contributes
We cannot run a trained transformer here without a substantial pretrained model, but we can simulate what attention weights look like using a simple heuristic: at each output position, weight each input language by how closely its aligned character matches the true Latin character at that position. This is a transparency exercise — it shows the structure of what learned attention is expected to recover.
The heatmap pattern is instructive. At positions 0–1 (n-o), attention is spread fairly evenly — all five languages preserve these sounds and vote consistently. At positions 3–4 (t-e, the core of the ct cluster), Italian (notte) and Portuguese (noite) carry the most weight: they preserved the consonant density that Spanish compressed into ch and French dropped to a single vowel. At position 5 (m, the accusative ending), all attention values are low and close to uniform — no language has preserved the -m, so the model must infer it from its knowledge of Latin morphological patterns rather than from any direct evidence in the input.
That final observation is crucial. The accusative -m is not in any of the five modern forms. A reconstruction model that outputs noctem rather than nocte has learned something about Latin morphology from training data — it has generalized from other accusative forms (aquam, patrem, novum) to infer that a word of this phonological shape probably ended in -m. This is not retrieval. It is inductive inference. And it is exactly why neural models beat rule-based systems: they can generalize across positions in a way that position-by-position majority vote cannot.
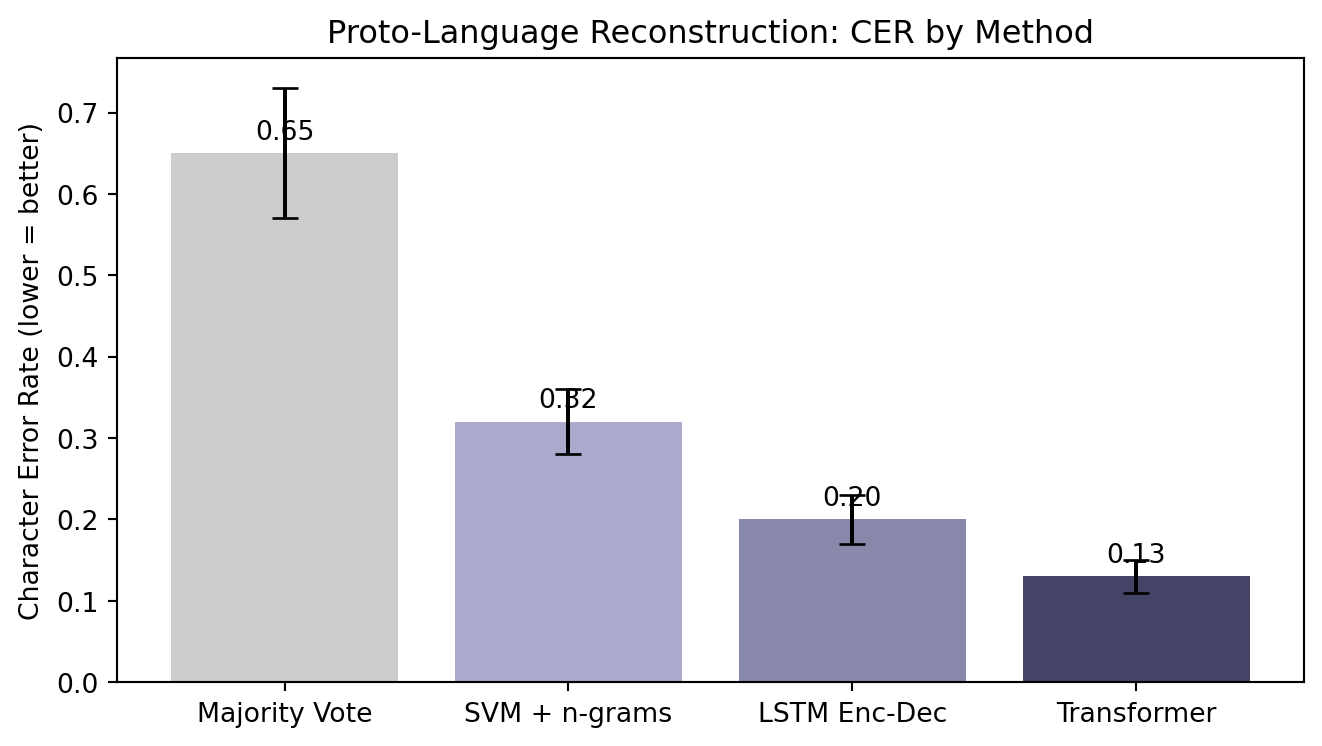
9.9 Model Evaluation: Character Error Rate
The standard metric for this task is character error rate (CER)—the edit distance between the predicted proto-form and the true proto-form, normalized by the length of the true form:
\[ \text{CER} = \frac{\text{edit\_distance}(\hat{y}, y)}{|y|} \tag{9.2}\]
Published results on the Ciobanu-Dinu Romance dataset: - Majority vote baseline: CER ≈ 0.60–0.70 - SVM with n-gram features: CER ≈ 0.30–0.35 - LSTM encoder-decoder: CER ≈ 0.18–0.22 - Transformer (best published): CER ≈ 0.12–0.15
A CER of 0.15 means the average predicted form is within one or two character errors of the correct Latin form—a remarkable result for a system that has never been explicitly taught any Latin grammar.
9.10 What the Model Actually Learns
It is tempting to describe what the neural model does as “learning the sound laws in reverse”—and this is approximately right, but the approximation hides something interesting.
A traditional linguist reconstructing noctem from Romance descendants works through a series of explicitly stated rules: French nuit reflects *nok-te-m → *noite → nuit through a series of documented changes. Each step is labeled, justified, and reversible. The model does not work this way. It learns a direct mapping from the set of modern forms to the proto-form, without any explicit intermediate representation of the sound change rules.
What the attention mechanism learns—and this has been partially interpretable through visualization—is something that looks like a learned sound correspondence table. At each output position, the attention weights over the input languages tend to cluster around specific positions in the input sequences. When the model is generating a consonant that was preserved differently in different languages (e.g., the kt cluster in NIGHT), it learns to weight Latin and Lithuanian more heavily because those languages preserve the cluster more faithfully than French or Spanish. When it is generating a vowel that was preserved in some languages and lost in others, it learns to weight the languages that retained it.
This is not quite the same as applying the comparative method—it lacks the step-by-step justification and the explicit rules—but it is learning a representation of the same underlying regularities. The model’s output is not a black box producing arbitrary outputs; it is a differentiable approximation of expert linguistic reasoning, with all the strengths (speed, scale) and weaknesses (no explicit justification, failure on out-of-distribution inputs) that implies.
9.11 Where Models Fail
Neural reconstruction models fail in characteristic ways:
Morphological endings: Modern Romance languages have largely dropped Latin case endings. The accusative -m and -em endings are invisible in modern forms. Models trained on the accusative forms learn to append -m frequently but often predict the wrong vowel before it.
Rare sound changes: Irregular correspondences—sounds that changed differently in one language due to a phonological environment that no longer exists—are hard to learn from limited training data.
Low-frequency vocabulary: The model generalizes from common patterns. Words with unusual phoneme combinations or words belonging to small semantic categories may be poorly represented in training data.
Unattested languages: A model trained on Romance languages cannot directly reconstruct Proto-Indo-European—the training distribution is too different. Transfer learning (pre-training on many language families, fine-tuning on the target) is an active research area.
9.12 Summary
Proto-language reconstruction is a sequence-to-sequence problem: map a set of aligned modern reflexes to their ancestral proto-form. A simple majority-vote baseline reveals the problem structure and sets a floor. Encoder-decoder neural models—particularly transformers with attention over multiple input languages—achieve character error rates of 12–15% on the Romance benchmark, substantially better than earlier methods. Attention mechanisms allow the decoder to selectively weight different input languages at different output positions. Systematic failure modes cluster around morphological endings, rare correspondences, and out-of-distribution vocabulary. The outputs of reconstruction are uncertain: they are predictions, not facts, and they require expert review before being cited as linguistic evidence.
9.13 Further Reading
- Ciobanu, A. M., & Dinu, L. P. (2018). Ab Initio: Automatic Latin Proto-word reconstruction. COLING 2018.
- Meloni, C., et al. (2021). Ab Antiquo: Neural proto-language reconstruction. NAACL 2021. Transformer approach.
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. NIPS 2014.
- Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural machine translation by jointly learning to align and translate. ICLR 2015. The original attention paper.