| Concept | Latin | Spanish | French | Italian | Portuguese | |
|---|---|---|---|---|---|---|
| 0 | one | unus | uno | un | uno | um |
| 1 | two | duo | dos | deux | due | dois |
| 2 | water | aqua | agua | eau | acqua | água |
| 3 | fire | ignis | fuego | feu | fuoco | fogo |
| 4 | hand | manus | mano | main | mano | mão |
| 5 | eye | oculus | ojo | oeil | occhio | olho |
| 6 | name | nomen | nombre | nom | nome | nome |
| 7 | mouth | os/oris | boca | bouche | bocca | boca |
| 8 | night | nox | noche | nuit | notte | noite |
| 9 | new | novus | nuevo | nouveau | nuovo | novo |
3 The Comparative Method
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Apply the comparative method step-by-step to a set of cognates
- Identify sound correspondences from parallel data
- Explain what makes a sound change “regular” and why regularity matters
- Reconstruct a proto-phoneme from its modern reflexes
- Recognize the limitations and failure modes of the traditional approach
- Visualize sound change correspondences as a mapping table
3.1 The Crime Scene
Imagine arriving at an archaeological dig where the only surviving artifacts are the words. No pottery, no bones, no inscriptions—just the vocabulary of a dozen languages that happened to be related, preserved in the mouths of their modern speakers. Your job is to determine: what language did they all descend from? What did that language sound like? When did the various descendants begin to diverge?
This is not a metaphor. It is precisely the problem that faced the German philologist Jakob Grimm in the early nineteenth century, and the solution he devised—which now bears his name as Grimm’s Law—was the moment historical linguistics became a science.
Grimm noticed something that had been sitting in plain sight for anyone who cared to look. The Germanic languages—Gothic, Old English, Old High German, Old Norse—had systematically different consonants from Latin, Greek, and Sanskrit in corresponding words. Not randomly different. Systematically different, with a consistent mapping:
- Latin p → Germanic f (Latin pater, Gothic fadar)
- Latin t → Germanic th (Latin tres, English three)
- Latin k → Germanic h (Latin cornu, English horn)
This was not accident. This was sound change: a systematic shift in how an entire population pronounced a class of consonants, spreading through a speech community over generations like a slow-moving wave.
The comparative method is the technique for reading these waves backward—tracing from the modern shoreline back to the stone that fell in the water.
3.2 Grimm’s Law in Detail
It is worth pausing to appreciate what Grimm actually described, because it is more elegant than a simple list of correspondences suggests.
The Indo-European stop consonants—the sounds you make by briefly closing the airstream completely—come in three varieties: voiceless stops (p, t, k), voiced stops (b, d, g), and voiced aspirates (bʰ, dʰ, gʰ, pronounced with a puff of air following the closure, like the bh in Sanskrit bhrata, “brother”). Grimm’s Law describes a rotation among these three categories in the Germanic languages:
- Voiceless stops became fricatives: PIE p → f, PIE t → þ (as in think), PIE k → h
- Voiced stops became voiceless stops: PIE b → p, PIE d → t, PIE g → k
- Voiced aspirates became voiced fricatives, then voiced stops: PIE bʰ → b, PIE dʰ → d, PIE gʰ → g
Each set of sounds shifted into the slot vacated by the preceding set—like a chain of musical chairs. Voiceless stops moved toward fricatives, making room for voiced stops to move into the vacated positions, making room for voiced aspirates to simplify into plain voiced stops. The elegance of this rotation is what convinced nineteenth-century linguists they were dealing with a real phenomenon and not a coincidence. Random changes do not rotate. Systematic physical changes of articulation might.
A quick sampling of the correspondences in action:
| PIE root | Meaning | Latin | English (reflex) |
|---|---|---|---|
| *pōds | foot | pēs/pedis | foot |
| *piscis | fish | piscis | fish |
| *ph₂tḗr | father | pater | father |
| *treies | three | trēs | three |
| *deḱm̥ | ten | decem | ten |
| *gʷen- | woman | - | queen |
| *ḱerd- | heart | cor/cordis | heart |
Every p in the Latin column corresponds to an f in the English column. Every t corresponds to a th or t sound depending on position. The pattern holds without exception across thousands of word pairs.
3.3 Verner’s Law: The Exception That Confirmed the Rule
If Grimm’s Law was the triumph of regularity, Verner’s Law was its vindication.
Within years of Grimm’s formulation, scholars noticed a problem: some words that should have followed Grimm’s Law did not. Latin pater becomes English father as expected—but Latin frater becomes English brother, not frother. The t in frater became a th in some Germanic words but a d or ð in others. Was the principle of regularity already failing?
In 1875, a young Danish linguist named Karl Verner proposed an answer. The exceptions were not random. They clustered in words where the Indo-European accent (stress) fell in a particular position. Germanic languages inherited the Indo-European pitch accent before the accent was later regularized to the first syllable. Words where the accent fell immediately before the consonant in question followed Grimm’s Law; words where the accent fell elsewhere underwent a different change.
The point was not just that Verner had explained the exceptions. The point was that the exceptions were themselves regular—governed by a rule that had simply not been discovered yet. This confirmed the Neogrammarian position more strongly than Grimm’s Law itself had done: apparent exceptions are almost always the result of an undiscovered conditioning factor, not evidence that sound change is irregular. This methodological principle—hunt for the rule before declaring an exception—remains the working assumption of historical linguistics to this day, and it is embedded in the way we build automated cognate detection systems.
3.4 Step-by-Step: The Four Operations
The comparative method proceeds in four operations, applied iteratively.
3.4.1 1. Collect a Wordlist of Basic Vocabulary
The first step is deliberate conservatism. Basic vocabulary—words for body parts, numerals, kinship terms, common natural phenomena—changes more slowly than specialized vocabulary. You do not start with words for “television” or “algorithm.” You start with words for MOTHER, HAND, THREE, WATER, FIRE.
The classic standard is the Swadesh list: 100 or 207 concepts selected by Morris Swadesh in the 1950s for their cross-linguistic stability. We will use a reduced version for illustration.
3.4.2 2. Identify Cognate Sets
A cognate set is a group of words—one per language—that all descend from the same proto-word. In the table above, the words for WATER are not all cognates: Spanish agua and Italian acqua trace to Latin aqua, but French eau traces to the same Latin word via a drastically eroded path (Latin aqua → Old French ewe → French eau). They are still cognates—just with more weathering on one of them.
The test for cognacy is not similarity. It is systematic similarity, explained by known or discoverable sound changes. English night and Greek nýks look very different, but they are cognates; English day and Latin dies look superficially similar, but the etymology is more complicated. Surface similarity is a clue, not a verdict.
3.4.3 3. Establish Sound Correspondences
This is the analytical core of the method. Take all your cognate pairs and line up which sound in language A corresponds to which sound in language B.
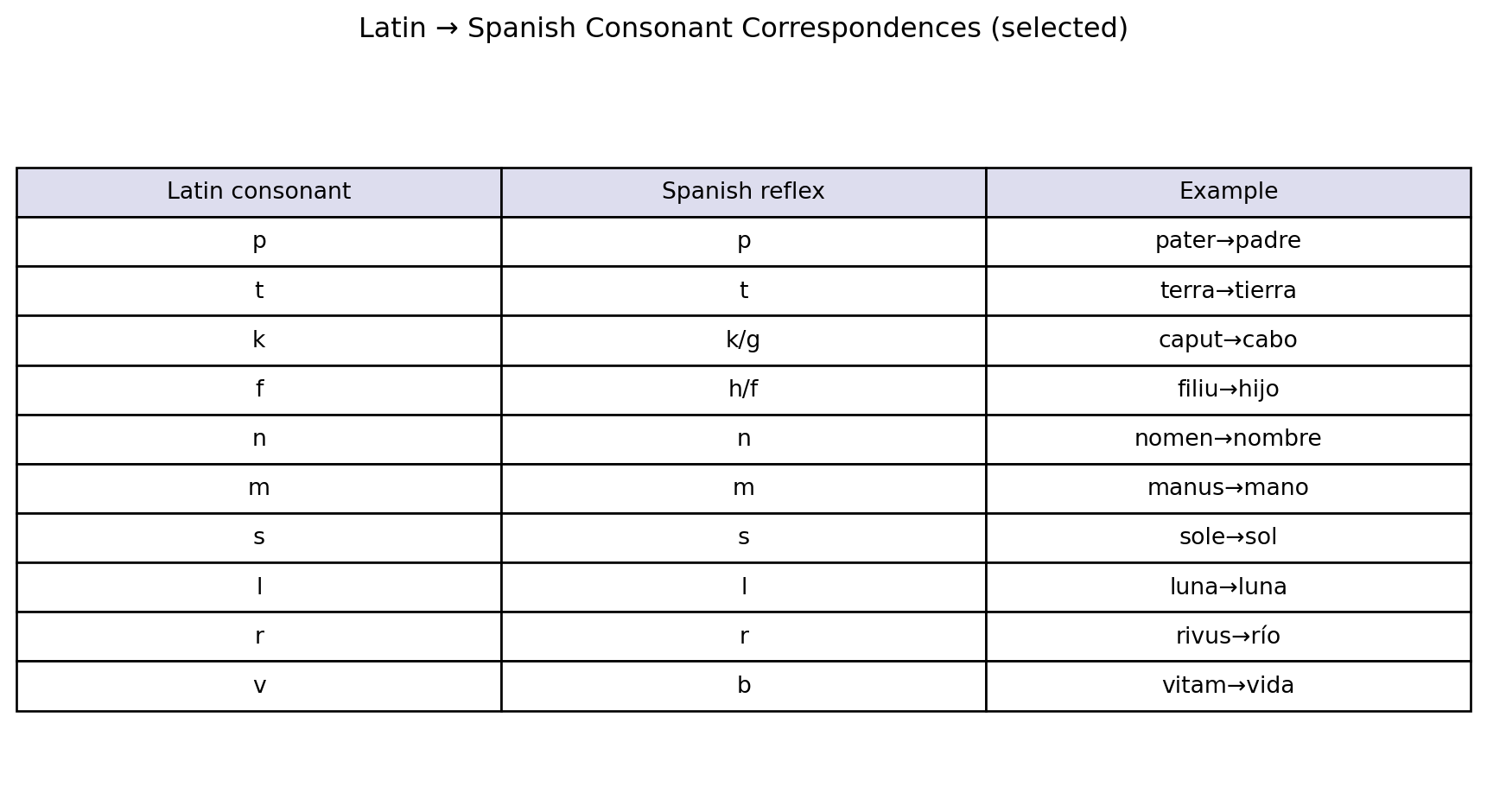
The key insight is regularity. If Latin f becomes Spanish h in one word (Latin filiu → Spanish hijo, “son”), it must become h in every word where the same conditions hold—otherwise the change is not a law, it is an accident. Jakob Grimm’s insight was that the Germanic consonant shifts were regular in exactly this sense: every instance of Latin p in the right position became Germanic f, without exception.
When you find exceptions, you do not dismiss them. They are data. Either they reflect borrowing from another language (which skips the sound change), or they reflect a conditioned environment where the change behaved differently, or they reveal an error in your cognate identification. Exceptions are gifts.
3.4.4 4. Reconstruct the Proto-Form
Given the correspondences, you can work backward to what the ancestral sound must have been. If Spanish has p, French has p, Italian has p, and Latin has p, the proto-Romance form almost certainly had p. If one language has h where the others have f, the h is the locally innovated form; f is older.
The reconstruction is not a guess. It is the most parsimonious hypothesis that explains all the observed reflexes. Linguists write reconstructed forms with an asterisk: *pater for the Proto-Indo-European form of FATHER.
3.5 Why Regularity Is Not Obvious
It is worth pausing on the claim of regularity, because it is not something you would expect if you had not seen it demonstrated.
Languages are spoken by millions of people across a geographic area and a span of time. Sound changes spread like any other social behavior—not simultaneously, not uniformly, with geographic and social variation. Why would a change be regular, affecting every instance of a phoneme in the same environment?
The answer, proposed by the Neogrammarians in the 1870s and still essentially correct, is that sound change operates on the physical mechanism of speech production, not on the meaning of words. A shift from p to f is a change in how the mouth moves—from a full stop to a fricative—not a lexical decision. The mouth changes its habit. Every word that used that motion changes with it.
This is why exceptions tend to cluster: words borrowed from another language arrive after the change, so they do not carry its effects. Words used in very formal or religious contexts may be pronounced conservatively. These patterns are not noise; they are diagnostic.
3.6 A Worked Example: Reconstructing a Proto-Word
Let us trace a single reconstruction through the four operations, concretely.
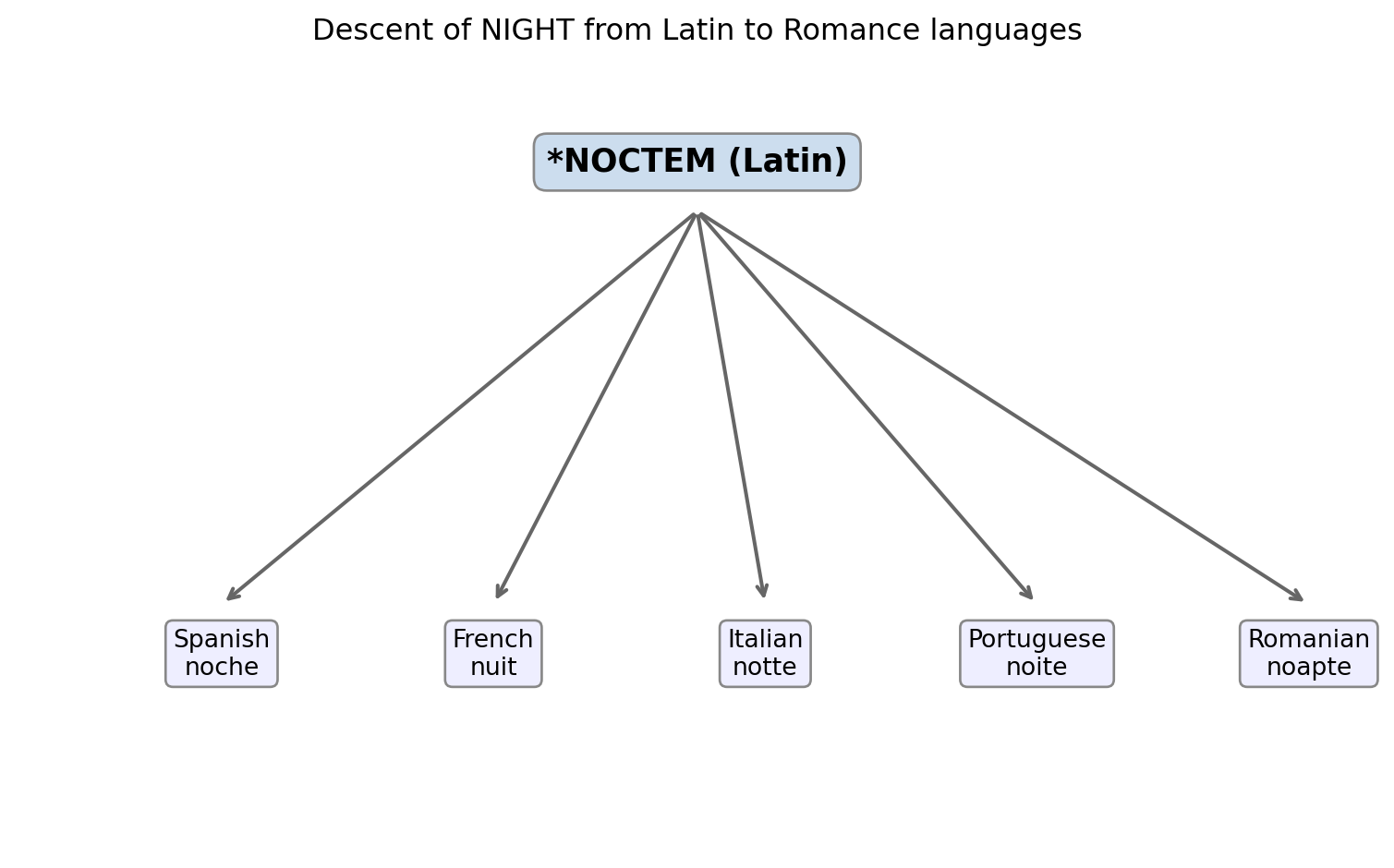
Target: Reconstruct the Proto-Indo-European word for NIGHT from its descendants.
Step 1 — Collect cognates:
| Language | Form | Romanization |
|---|---|---|
| Sanskrit | नक्त | nakta- |
| Greek | νύξ (gen. νυκτός) | nýks (gen. nyktos) |
| Latin | nox (gen. noctis) | nox |
| Gothic | nahts | nahts |
| Old English | niht | niht |
| Lithuanian | naktis | naktis |
| Old Irish | nocht | nocht |
Step 2 — Identify correspondences:
In word-initial position, all forms have n. This is the easiest call: *n.
The vowel in the first syllable varies: Sanskrit a, Greek y (which represents an older u-like sound), Latin o, Gothic/OE a. These are characteristic reflexes of a single PIE vowel, and comparison with other words exhibiting the same pattern points to *o.
The medial consonant cluster: Sanskrit kt, Greek kt (in the genitive nyktos), Latin ct, Gothic ht, Lithuanian kt, Old Irish cht. The variation kt / ct / ht / cht is exactly the pattern expected for a PIE sequence *kʷ (labiovelar) followed by *t.
The final consonant s appears in Greek, Latin, Gothic, Lithuanian—this is the nominative singular ending.
Step 3 — Reconstruct: Assembling the evidence: *nókʷts. The asterisk marks it as reconstructed; the diacritics mark accent and vowel quality.
Step 4 — Verify: When the Hittite archives were deciphered in the early twentieth century, scholars discovered the Hittite word for night was nekuz—consistent with an ancestor *nókʷts if you apply the sound changes of Anatolian languages. A prediction made from comparative work before Hittite was known turned out to be correct.
This is the comparative method at its best: not a guess, but a constrained inference that can be tested against newly discovered data.
Time depth. Sound changes accumulate. After roughly 8,000–10,000 years of separation, the resemblances between related languages may have eroded below the threshold of reliable detection. This is why reconstructing proto-forms deeper than Proto-Indo-European is controversial: there may be too little signal left in the noise.
Contact and borrowing. Languages that have been in prolonged contact contaminate each other’s vocabulary. The English word for “beef” comes from French; the French word for “week-end” comes from English. Borrowed words violate the regularity of sound changes because they arrived after the change, or from a different system altogether. Detecting and excluding loanwords is a nontrivial problem—and the subject of Chapter 9.
Parallelism. Sometimes similar-looking words in different languages developed independently from different roots. English day and Latin dies superficially resemble each other but are not cognates in the straightforward sense. These false cognates (or coincidental resemblances) can mislead analysis.
Documentation gaps. For most of human linguistic history, we have no written records. The comparative method can only work with data that was recorded—which biases it heavily toward languages spoken by literate civilizations.
3.7 Automating Correspondences
Here is the connection to data science that will become central in later chapters. The correspondence table we drew manually can be derived algorithmically: line up cognate pairs, count which sound in language A co-occurs with which sound in language B, build a matrix.
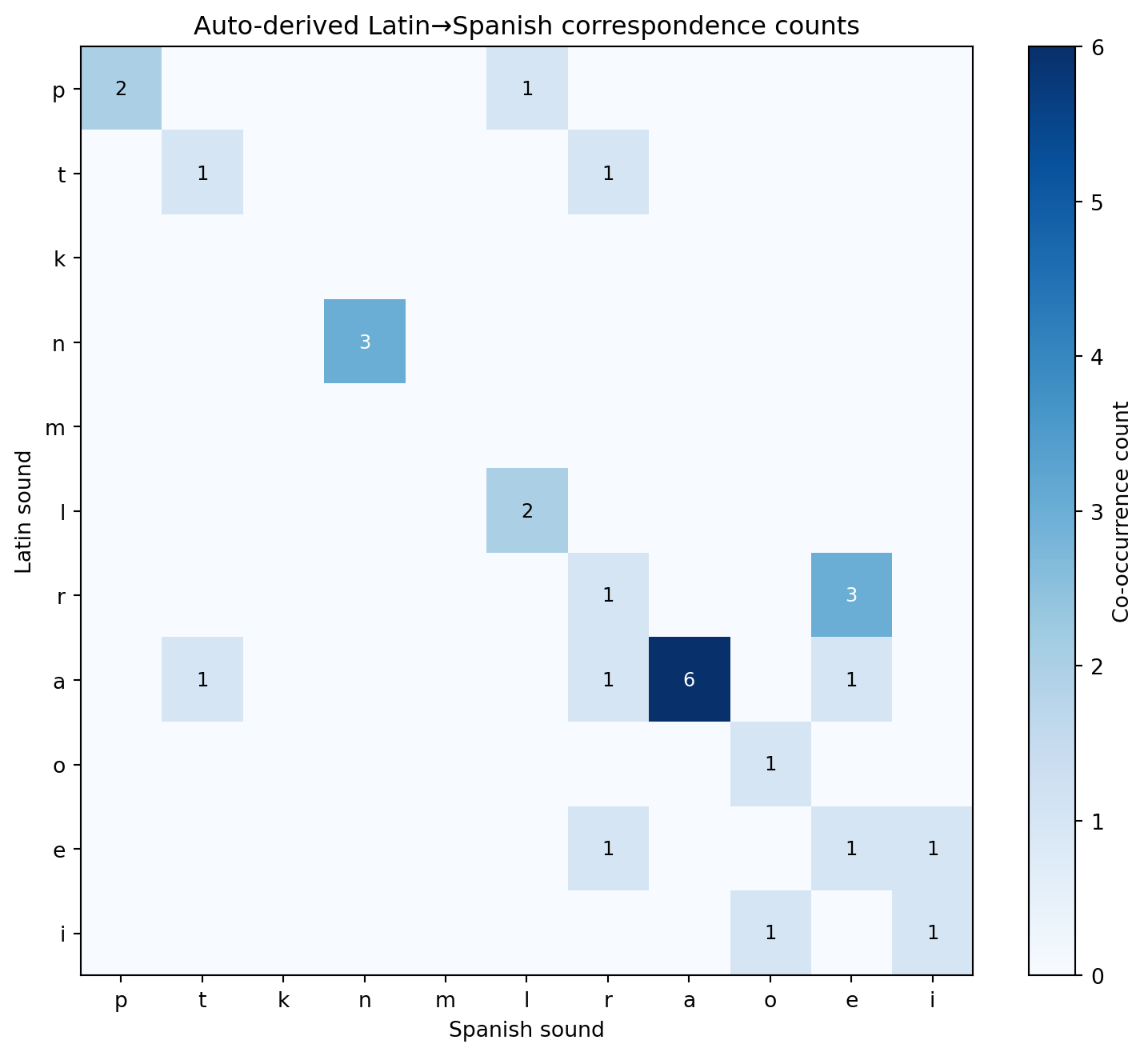
The diagonal dominates—sounds tend to be preserved—but the off-diagonal entries tell the story of change. With a larger dataset, this matrix becomes the foundation of automated sound correspondence discovery, which we will build in Chapters 4 and 5.
3.8 Summary
The comparative method works in four steps: collect a basic wordlist, identify cognate sets, establish systematic sound correspondences, and reconstruct the proto-form as the most parsimonious explanation of those correspondences. Regularity—the principle that sound changes are exceptionless—is the method’s core commitment. Exceptions exist and are informative, clustering around borrowing, conservative usage, and conditioned environments. The method has real limits: it loses resolution at great time depths, is confounded by contact and borrowing, and requires sufficient documentation. All four limitations become targets for computational approaches in subsequent chapters.
3.9 Further Reading
- Fortson, B. W. (2010). Indo-European Language and Culture: An Introduction (2nd ed.). Wiley-Blackwell. Chapter 2 covers the comparative method with care.
- Hock, H. H., & Joseph, B. D. (2009). Language History, Language Change, and Language Relationship (2nd ed.). Mouton de Gruyter.
- Grimm, J. (1822). Deutsche Grammatik (2nd ed.). The original source for Grimm’s Law, in German.
- Verner, K. (1875). Eine Ausnahme der ersten Lautverschiebung. Zeitschrift für vergleichende Sprachforschung. Verner’s Law: the famous exception to Grimm’s Law that was itself regular.