12 LLMs & Modern Etymology
NoteLearning Objectives
By the end of this chapter, you will be able to:
- Explain the structured extraction problem for etymological data
- Design a prompt for extracting cognate relationships from dictionary entries
- Evaluate LLM output quality using precision/recall against human-annotated gold standards
- Describe the fine-tuning pipeline for a sequence-to-sequence model (FLAN-T5)
- Identify failure modes of LLMs for historical linguistics tasks
- Build a small structured etymology dataset from unstructured dictionary text
12.1 The Digital Haystack
The Online Etymology Dictionary (Etymonline.com) contains over 50,000 etymological entries. Wiktionary has millions more in dozens of languages. The Oxford Latin Dictionary runs to several thousand pages. The Etymologisches Wörterbuch des Deutschen fills two thick volumes. The Dictionary of American Regional English is five volumes. Put them together and you have, somewhere inside them, most of what is known about the historical development of the words of the world’s documented languages.
None of it is structured. It is prose—beautifully written, expert prose, but prose: unformatted text that no algorithm can query. To ask the digital archive “which English words derive from Proto-Indo-European *gʷen- (woman)?” you would have to read every entry by hand and extract the relationship yourself.
Large language models are, among other things, prose-reading machines. They have been trained on vast amounts of text that includes dictionary entries, etymological discussions, and linguistic scholarship. Whether that training gives them the ability to reliably extract structured etymological information—cognate relations, source language, approximate date of borrowing, direction of derivation—is an empirical question.
The answer, as of current models, is: yes, with significant caveats.
12.2 What LLMs Actually Know About Etymology
Before designing an extraction system, it is worth understanding what large language models actually know about etymology—and what they do not.
LLMs trained on internet-scale corpora have been exposed to an enormous amount of etymological content: dictionary entries, Wiktionary articles, linguistics papers, Wikipedia articles on language families, etymology discussion forums, and secondary sources that cite etymological information in passing. This means that a capable LLM, when presented with a common English word, can often produce accurate etymological information for it—not because it has learned linguistic rules, but because it has memorized information from its training data.
This creates an interesting asymmetry. For high-frequency words with well-documented etymologies—words like father, night, water, words that appear in every introduction to linguistics—a capable LLM’s output is likely to be accurate because the correct information appeared many times in training data. For low-frequency words, rare words, words from underdocumented languages, or words whose etymologies are genuinely contested, the model is likely to hallucinate: producing a plausible-sounding but incorrect etymology, often by analogy to a superficially similar word it does know well.
The practical implication for extraction systems is that coverage and accuracy are inversely related in a way that tracks word frequency. You can build a high-precision extraction system for common words by trusting the model’s output; you need extensive human review for uncommon words. This is not a defect of the model—it is an accurate reflection of the distribution of etymological knowledge in the text the model learned from. Common words have been studied more, written about more, and are better represented in both the model’s training data and in the gold-standard sources we would use for evaluation.
12.3 The Extraction Task
We want to convert unstructured dictionary prose into structured records.
Input (unstructured Etymonline entry):
awful (adj.) Old English egefull "inspiring awe, causing dread," from ege "awe"
(see awe) + -full (see -ful). Weakened sense of "very bad" (terrible, frightful)
is from 1800; colloquial sense of "exceedingly" is from 1818.Target output (structured JSON):
{
"word": "awful",
"pos": "adjective",
"language": "English",
"earliest_attested": "Old English",
"source_form": "egefull",
"source_language": "Old English",
"components": [
{"form": "ege", "meaning": "awe"},
{"form": "-full", "meaning": "-ful suffix"}
],
"sense_changes": [
{"period": "Old English", "meaning": "inspiring awe"},
{"period": "1800", "meaning": "very bad/frightful"},
{"period": "1818", "meaning": "exceedingly (colloquial)"}
]
}This structured form is queryable. Once you have it, you can ask: how many English words trace to Old English? How many sense changes happened in the 1800s? Which words have the most documented meaning shifts?
12.4 Prompt Engineering for Etymology Extraction
Before fine-tuning, we can use a capable LLM directly via prompt engineering. The key is being specific about the output format and providing clear examples.
Prompt (with entry substituted):
You are an expert etymologist. Extract structured etymological information from the following dictionary entry and return valid JSON only. Follow the schema exactly.
Schema:
{
"word": string,
"pos": string,
"earliest_attested": string,
"source_form": string,
"source_language": string,
"cognates": [{"form": string, "language": string}],
"sense_changes": [{"period": string, "meaning": string}]
}
Dictionary entry:
night (n.) Old English niht (West Saxon), neaht (Anglian),
the dark part of the day, from Proto-Germ...
JSON output:
Expected JSON output structure:
{
"word": "night",
"pos": "noun",
"earliest_attested": "Old English",
"source_form": "*naht-",
"source_language": "Proto-Germanic",
"cognates": [
{
"form": "naht",
"language": "Old Saxon"
},
{
"form": "naht",
"language": "Old High German"
},
{
"form": "nacht",
"language": "Dutch"
},
{
"form": "Nacht",
"language": "German"
},
{
"form": "nyx",
"language": "Greek"
},
{
"form": "nox",
"language": "Latin"
}
],
"sense_changes": []
}12.5 Evaluating Extraction Quality
The gold standard for evaluation is a human-annotated dataset: a linguist reads each entry and produces the correct structured output. The model’s output is compared to this gold standard using information extraction metrics.
Cognate extraction for 'night':
True Positives: 6
False Positives: 0
False Negatives: 4
Precision: 1.000
Recall: 0.600
F1: 0.75012.6 Fine-Tuning for Structured Extraction
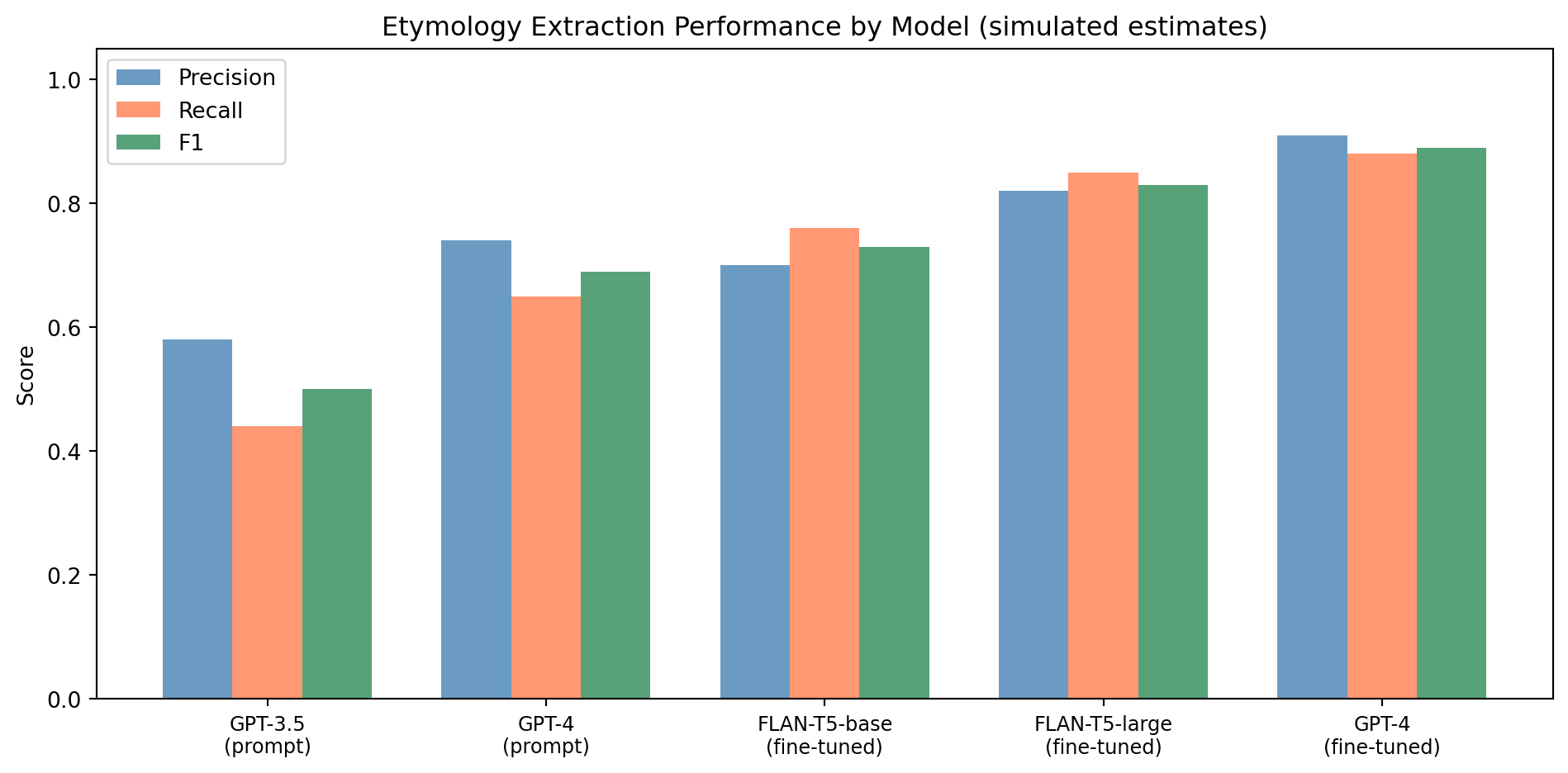
Prompt engineering alone has limitations: the model may generate invalid JSON, hallucinate cognates, or fail on rare entry formats. Fine-tuning on a small gold-standard dataset (a few hundred carefully annotated entries) dramatically improves reliability.
The standard approach uses FLAN-T5, a sequence-to-sequence model pre-trained for instruction following. The fine-tuning procedure is:
- Create training data: pairs of (dictionary entry text, target JSON)
- Format inputs: prepend the extraction instruction to the dictionary text
- Fine-tune: minimize the cross-entropy loss on the target JSON tokens
- Evaluate: measure precision, recall, F1 on a held-out test set
In practice, even 200–300 training examples produce meaningful improvement over zero-shot prompting, because fine-tuning teaches the model the exact JSON schema and the conventions of etymological text.
12.7 Failure Modes
LLMs fail in characteristic ways on etymology tasks.
Hallucinated cognates: The model may confidently assert a cognate relationship that does not exist, drawing on superficial phonetic similarity rather than historical evidence. English bad is not related to Persian bad (meaning “bad”)—they are a spectacular coincidence—but a model trained on general text may propose the connection.
Temporal confusion: Models often conflate Proto-Indo-European roots with their immediate descendants. The PIE root *ph₂tḗr is not the “Latin” form pater; it is the reconstructed ancestor. Models sometimes assign the wrong tier of the reconstruction to the cited form.
Script and diacritic errors: IPA transcriptions and reconstructed forms use characters that are underrepresented in typical training data. Models often drop diacritics or substitute familiar characters for unfamiliar ones.
Confidently wrong dates: Models may assert dates for semantic changes that are off by centuries, drawing on imprecise information in their training data rather than authoritative etymological scholarship.
The implication for practice: LLM extraction is a first pass, not a final product. Human expert review of a random sample is essential before trusting the extracted dataset for downstream analysis.
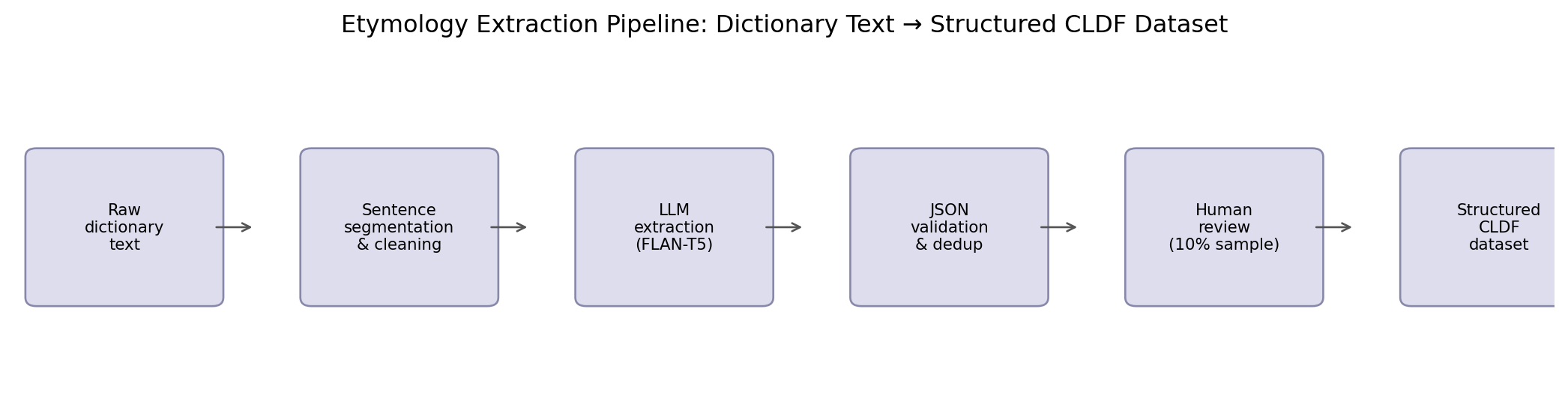
12.8 Building a Structured Etymology Dataset
The full pipeline for building a structured etymological dataset:
12.9 Summary
LLMs can extract structured etymological information from unstructured dictionary prose, achieving F1 scores of 0.65–0.90 on cognate extraction tasks depending on model size and whether the model has been fine-tuned. The extraction task requires careful prompt design, output format enforcement (JSON schema), and post-processing validation. Fine-tuning on even small gold-standard datasets meaningfully improves performance over zero-shot prompting. Systematic failure modes—hallucinated cognates, temporal confusion, diacritic errors, and incorrect dates—require human expert review of a random sample before the extracted data is trusted for downstream analysis. The output of the extraction pipeline is a structured CLDF-format dataset that enables the graph representations and queries of Chapter 11.
12.10 Further Reading
- Ciobanu, A. M., & Dinu, L. P. (2023). Automatic construction of etymological knowledge bases using large language models. Findings of ACL 2023.
- Chung, H. W., et al. (2022). Scaling instruction-finetuned language models. arXiv:2210.11416. FLAN-T5 model description.
- Brown, T. B., et al. (2020). Language models are few-shot learners. NeurIPS 2020. GPT-3 paper—establishes in-context learning as a baseline.
- Navigli, R., et al. (2023). BabelNet 5.0: Expanding the largest multilingual encyclopedic dictionary and semantic network. AI Magazine. A relevant large-scale structured resource.