Explain the core hypothesis of glottochronology and where it comes from
Apply the Swadesh formula to estimate divergence time from cognate counts
Implement a basic glottochronological calculator in Python
Describe the principal criticisms of constant-rate models
Distinguish classical glottochronology from modern Bayesian phylogenetic dating
Interpret divergence time estimates with appropriate uncertainty
8.1 The Clock in the Vocabulary
In 1952, Morris Swadesh, an American linguist with an unusually quantitative turn of mind, proposed something that struck most of his colleagues as either brilliant or absurd, depending on their disposition toward mathematics. Languages, he argued, lose basic vocabulary at a roughly constant rate. Not all vocabulary — not the technical terms, the slang, the borrowed words — but a specific core list of concepts so fundamental to human experience that every language has words for them and almost none have reason to replace them quickly. If this rate were truly constant, then counting how many words two related languages still shared from this core list would let you calculate when they parted ways, just as counting the remaining atoms of carbon-14 in an organic sample lets you calculate when the organism died.
Swadesh was proposing, in effect, a linguistic molecular clock.
The analogy to radiocarbon dating is instructive and, like all analogies, imperfect. Carbon-14 decays at a rate governed by quantum mechanics — a rate that does not depend on temperature, pressure, chemistry, or the history of the sample. Vocabulary replacement is governed by culture, contact, prestige, war, and a hundred other contingencies. The question Glottochronology asks — and seventy years of subsequent work has answered only partially — is whether, despite all this noise, the average rate is stable enough to be useful.
8.2 The Swadesh List
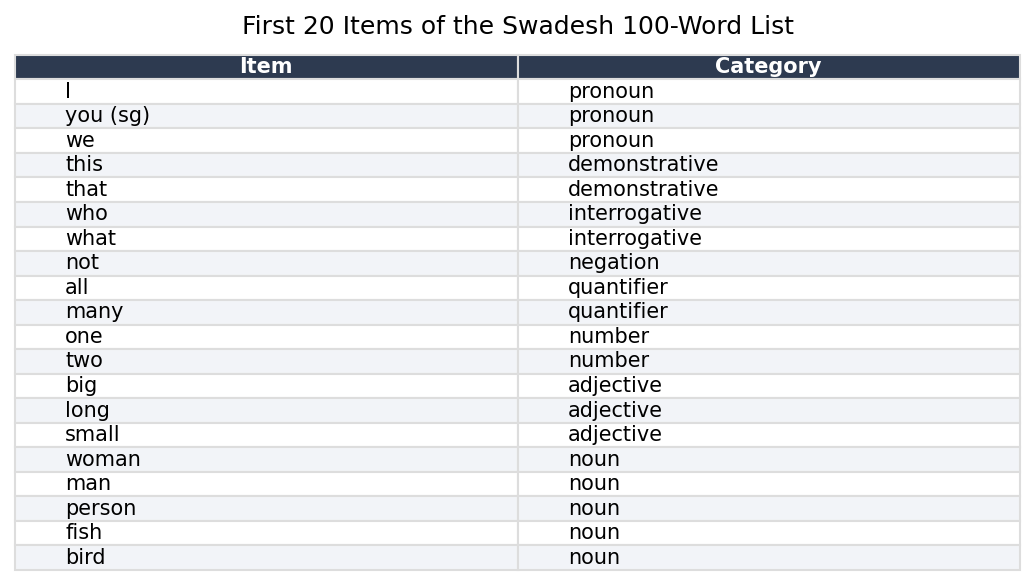
The foundation of glottochronology is the Swadesh list: a set of concepts chosen specifically for their universality and resistance to borrowing. Swadesh’s original 1952 list had 215 items; he revised it to 200, then to 100. The 100-item list has become the standard for computational work because it is more carefully curated and shows better cross-linguistic stability.
The criteria for inclusion on the list are stringent. A concept must be:
Universal: every human language has a word for it
Concrete: it refers to something in immediate experience, not an abstraction
Resistant to borrowing: languages rarely adopt foreign words for these concepts
Resistant to derivation: the word is typically a root, not a compound or derivative
The list includes pronouns (I, you, we), body parts (hand, eye, blood, tongue), basic natural phenomena (water, fire, sun, moon, night), elementary actions (to eat, to drink, to die, to come), and basic properties (big, small, new, old, full). It deliberately excludes culturally specific items (plough, king, temple), technical vocabulary (wheel, sword, coin), and anything that might be easily borrowed.
First 20 items of the Swadesh 100-word list, showing the categories from which core vocabulary is drawn.
The words on the list are not translations of English into other languages — they are instantiations of the concept in each language’s own vocabulary. The English word for HAND is hand. The corresponding word in classical Latin is manus. In Proto-Germanic, the reconstructed form is *handuz. These are cognates — different reflexes of the same ancestral word — and they count as a match in the glottochronological comparison. The French main (also from manus) and the English hand (from *handuz) are not cognates and count as a non-match, reflecting the split between the Romance and Germanic branches of Indo-European.
8.3 The Basic Formula
Swadesh’s core claim was that the basic vocabulary items in his list are replaced at a rate of approximately 14% per thousand years — meaning that after 1000 years, a language retains about 86% of its original core vocabulary, having replaced the other 14% with new or borrowed words. After 2000 years, it retains roughly \(0.86^2 \approx 74\%\). After 5000 years, roughly \(0.86^5 \approx 47\%\).
If two daughter languages descended from a common ancestor and each lost vocabulary at this rate independently, the proportion of cognates they share at time \(t\) (measured in millennia since their split) is:
\[C(t) = r^{2t}\]
where \(r\) is the retention rate per millennium (\(r \approx 0.86\) in Swadesh’s original estimate) and \(t\) is the elapsed time in thousands of years. The factor of 2 in the exponent appears because both languages have been diverging for time \(t\), each independently replacing vocabulary.
Inverting this equation to solve for \(t\) given an observed cognate percentage \(C\):
\[t = \frac{\log C}{2 \log r}\]
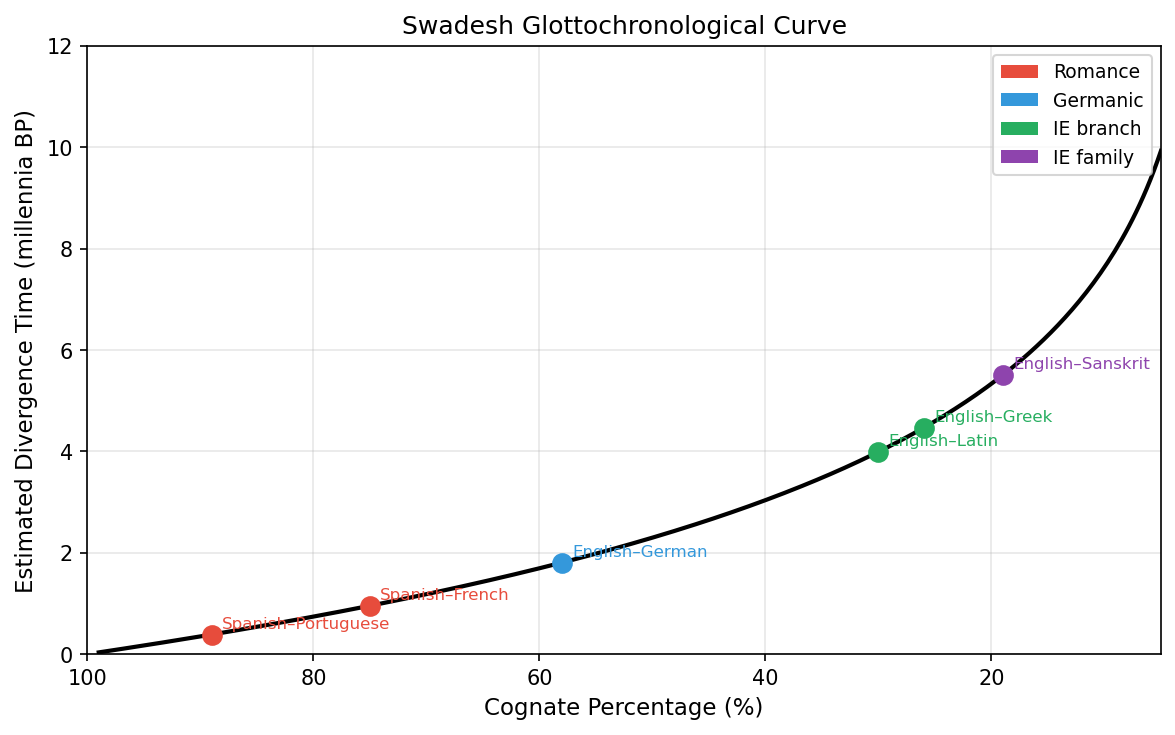
This is the Swadesh glottochronological formula. Given two related languages and a count of how many of the 100 Swadesh items are cognates, you can estimate when they split.
The Swadesh glottochronological curve mapping cognate percentage to estimated divergence time. Real language pairs are plotted for comparison against the theoretical curve.
8.4 Implementing Glottochronology in Python
The calculation itself is straightforward. The difficulty lies in the data: obtaining reliable cognate judgments for the 100 Swadesh items across the language pairs of interest.
import numpy as npdef glotto_time(n_cognates: int, n_total: int=100, r: float=0.86) ->float:""" Estimate divergence time using the Swadesh formula. Parameters ---------- n_cognates : int Number of cognate pairs identified in the Swadesh list. n_total : int Total number of Swadesh items compared (default 100). r : float Retention rate per millennium (default 0.86, Swadesh original). Returns ------- float Estimated time of divergence in thousands of years BP. """ C = n_cognates / n_totalif C <=0or C >=1:raiseValueError("Cognate proportion must be strictly between 0 and 1.")return np.log(C) / (2* np.log(r))def glotto_ci(n_cognates: int, n_total: int=100, r: float=0.86, alpha: float=0.05) ->tuple:""" Approximate confidence interval for divergence time using the binomial standard error on the cognate proportion. Returns (lower_bound, point_estimate, upper_bound) in millennia. """from scipy import stats C = n_cognates / n_total se = np.sqrt(C * (1- C) / n_total) z = stats.norm.ppf(1- alpha /2) C_lo =max(C - z * se, 0.01) C_hi =min(C + z * se, 0.99) t_point = glotto_time(n_cognates, n_total, r) t_lo = np.log(C_hi) / (2* np.log(r)) # more cognates → more recent t_hi = np.log(C_lo) / (2* np.log(r)) # fewer cognates → more ancientreturn (t_lo, t_point, t_hi)# Example: English vs German — approximately 58 cognates out of 100pairs = {'Spanish–Portuguese': 89,'Spanish–French': 75,'English–German': 58,'English–Latin': 30,'English–Sanskrit': 19,}print(f"{'Language Pair':<25}{'Cognates':>8}{'t (ka)':>8}{'95% CI':>20}")print("-"*65)for pair, n in pairs.items(): lo, t, hi = glotto_ci(n)print(f"{pair:<25}{n:>8}{t:>6.2f} ({lo:.2f} – {hi:.2f})")
The output makes the method’s limitations immediately visible. The 95% confidence interval for English–German (58 cognates) spans several hundred years on either side of the point estimate — and that uncertainty assumes the only source of error is sampling noise in the cognate count. In reality, the cognate judgments themselves are uncertain, the retention rate is not fixed, and the model is misspecified. The true uncertainty is considerably larger.
8.5 The Retention Rate Problem
The most fundamental criticism of classical glottochronology is that the retention rate is not constant. Swadesh’s \(r = 0.86\) was estimated from a small set of languages with known historical divergence dates — languages like Romance (split from Latin in a datable period) and the modern Germanic languages. Applying the same rate universally assumes that Polynesian languages, Bantu languages, and Tibeto-Burman languages lose core vocabulary at the same speed as the Indo-European languages used to calibrate the formula.
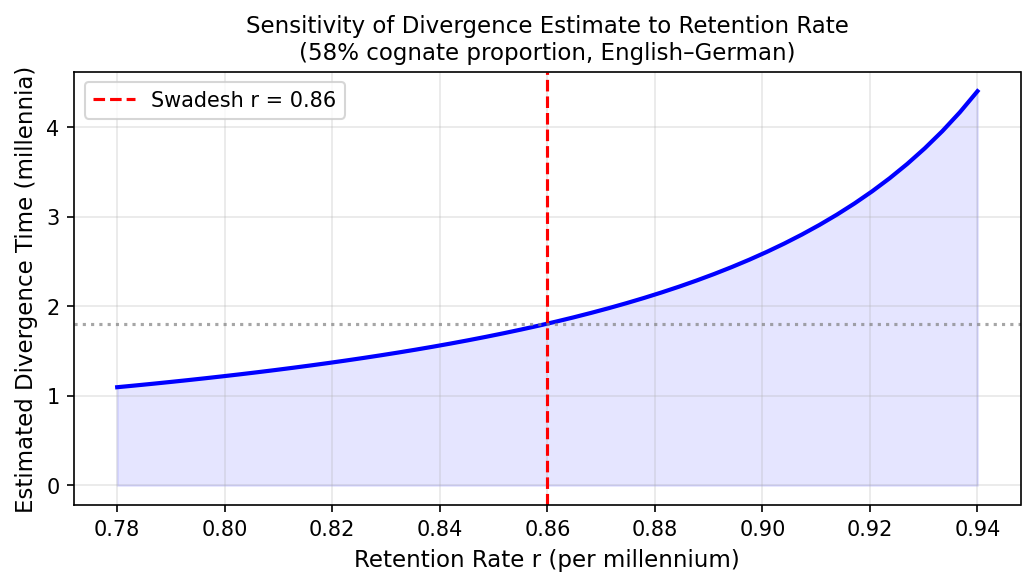
They do not. Estimated retention rates from well-dated language pairs cluster around 0.80 to 0.92, a range wide enough to produce wildly different divergence estimates. If the true retention rate for a given language family is 0.80 rather than 0.86, the formula will systematically overestimate divergence times. If it is 0.92, it will underestimate them.
Sensitivity of the divergence time estimate to the assumed retention rate. For English–German (58% cognates), the estimate ranges from under 2 to over 4 millennia depending on which retention rate is assumed.
A second criticism targets the independence assumption. The formula assumes that vocabulary replacement in the two daughter languages is statistically independent after the split. In practice, languages that separated geographically but remained in contact — through trade, migration, or conquest — will show artificially elevated cognate counts, pushing the estimated divergence time toward the present. Conversely, languages that experienced rapid cultural upheaval (conquest, mass bilingualism, prestige contact) may lose basic vocabulary faster than the model predicts, pushing estimated divergence times into the past.
A third, more subtle criticism is that cognate identification is itself theory-laden and error-prone. Two words are cognates if and only if they descend from the same ancestral form — not merely if they sound similar. The German Vater and English father are cognates (both from Proto-Germanic *fadēr, itself from PIE *ph₂tḗr). The English much and the German mächtig (powerful) look similar and share an ancestor, but they are not cognates of each other in the relevant sense — they descended through different semantic paths from the same root. Expert cognate judgments disagree at rates of 10–20% on difficult cases, introducing systematic bias whose direction is hard to assess.
8.6 Bayesian Phylogenetic Dating: The Modern Approach
The contemporary response to classical glottochronology’s weaknesses is Bayesian phylogenetic dating, pioneered in linguistics by Russell Gray and Quentin Atkinson in a landmark 2003 paper in Nature that estimated the age of the Indo-European language family using methods adapted from evolutionary biology.
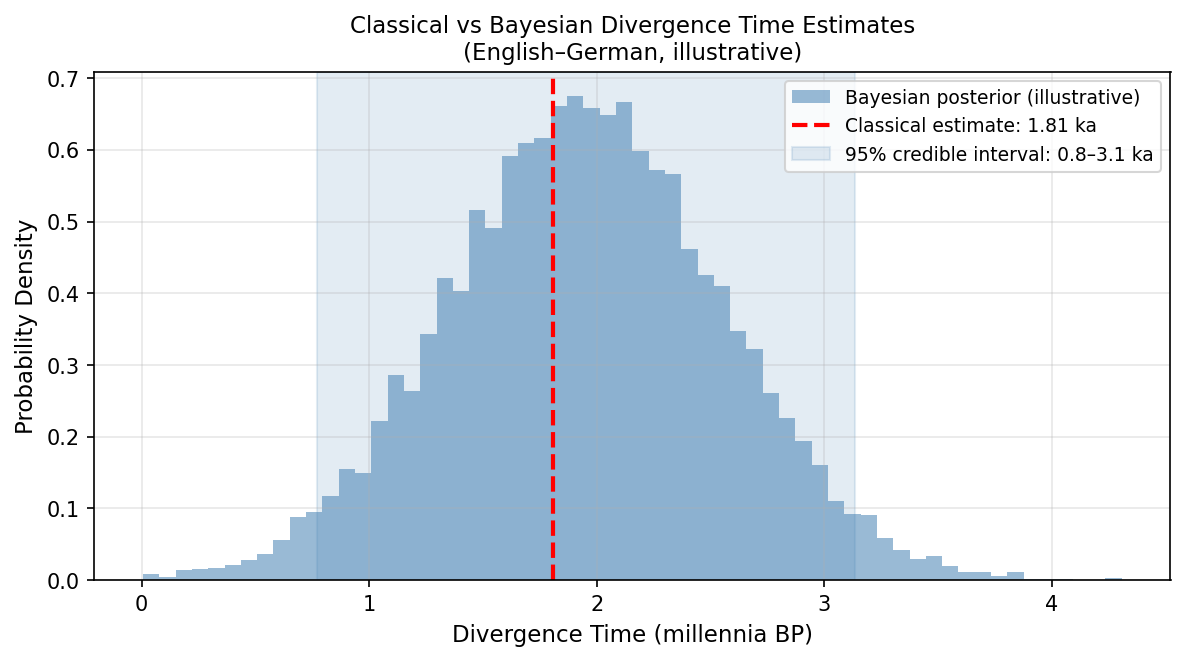
Rather than assuming a fixed retention rate and deriving a point estimate, Bayesian dating places a prior distribution over the tree topology, the branch lengths, and the substitution rate, and then uses Markov Chain Monte Carlo (MCMC) sampling to estimate the posterior distribution over all parameters simultaneously. The result is not a single number but a full probability distribution over possible divergence times — a distribution that properly propagates all sources of uncertainty.
The key innovations in the Bayesian approach are:
Rate relaxation. Instead of a single global retention rate, the Bayesian model allows each branch of the phylogenetic tree to have its own rate, drawn from a common prior distribution. This is the “relaxed clock” model, directly analogous to the relaxed molecular clock used in genomic phylogenetics. Languages that underwent rapid change get longer branch lengths; languages that changed slowly get shorter ones. The model learns the rate distribution from the data rather than assuming it.
Calibration constraints. Rather than calibrating the clock from a single assumed rate, Bayesian dating incorporates multiple calibration points — language pairs or nodes in the tree whose divergence time is known from historical records, inscriptions, or archaeological evidence. The Romance languages provide a calibration: they diverged from Latin after the fall of the Western Roman Empire, giving a hard minimum bound of roughly 1500 years. The Germanic languages provide another. Each calibration constrains the model independently, and the posterior integrates all of them.
Topological uncertainty. Classical glottochronology assumes the tree topology is known. Bayesian methods treat the topology as an unknown parameter and sample over all possible trees, weighted by how well they fit the data. The resulting estimate of divergence time averages over topological uncertainty rather than conditioning on a single assumed tree.
The Gray and Atkinson analysis, using 87 Indo-European languages and 2449 cognate sets, estimated the age of Proto-Indo-European at approximately 8500 years before present, supporting the Anatolian origin hypothesis over the competing Pontic-steppe hypothesis (which would require an age of 5000–6000 years). The result was controversial — the steppe hypothesis remains the majority view among archaeologists — but the methodological advance was unambiguous. Bayesian phylogenetic dating replaced a single number with a credible interval, replaced a fixed rate with a learned distribution, and replaced topological assumption with topological inference.
Comparison of a classical point estimate with a Bayesian posterior distribution for the English–German divergence time. The Bayesian approach properly represents uncertainty rather than collapsing it to a single number. (Posterior shown is illustrative; real results require MCMC sampling over the full tree.)
8.7 What the Numbers Actually Mean
Even a well-calibrated Bayesian divergence time estimate does not answer the question most people think it answers. A divergence time of 1500 years for English and German does not mean that their speakers stopped understanding each other 1500 years ago. Proto-Germanic speakers were already differentiating into Proto-West-Germanic and Proto-North-Germanic dialects long before the historical dates we can pin down. The divergence time estimated by any method is the time since the most recent common ancestor of the two languages — a point that is itself a reconstruction, not an observable event.
More importantly, divergence of linguistic lineages is not the same as separation of populations. Languages can diverge while their speakers remain in contact; they can also converge while their speakers are geographically separated (through shared prestige norms, religious texts, or broadcast media). The linguistic clock runs at a rate determined by cultural and social dynamics, not by geography or genetics.
The practical value of glottochronological methods — classical or Bayesian — is not that they give precise calendar dates. It is that they provide relative ordering information (this split is older than that one) and rough scale information (this family is ancient enough to have predated the development of agriculture; that one is young enough to postdate Roman conquest). Within those limits, used alongside archaeological and genetic evidence, they are genuinely useful tools for reconstructing the deep human past.
8.8 Summary
Glottochronology uses the rate of replacement in core vocabulary — operationalized through the Swadesh 100-word list — to estimate when two related languages diverged from their common ancestor. The Swadesh formula \(t = \log C / (2 \log r)\) converts an observed cognate proportion \(C\) into a divergence time in millennia, assuming a fixed retention rate \(r \approx 0.86\). The method is simple to implement and provides useful first-order estimates, but it is sensitive to the assumed retention rate, violated by language contact, and undermined by the inherent uncertainty in cognate identification. Modern Bayesian phylogenetic dating addresses these weaknesses by treating the retention rate as a learnable parameter, incorporating multiple calibration constraints from historical evidence, and producing full posterior distributions over divergence time rather than point estimates. The result is not certainty — language history is too contingent for that — but calibrated uncertainty, which is the honest epistemic state of anyone doing quantitative historical linguistics.