Causal Inference, Bayesian Reasoning, and the Science of Learning
Author
Troy Altus
Published
May 1, 2026
NoteLearning Objectives
Understand what we mean by learning in both human and machine contexts
Distinguish between the three major frameworks for reasoning under uncertainty
Appreciate why causal thinking is fundamentally different from statistical pattern-matching
Get a map of the book’s five-part journey
0.1 The Oracle Problem
In the summer of 1854, a physician named John Snow did something that was, at the time, considered deeply strange. There was a cholera epidemic tearing through the Soho district of London, and Snow did not reach for the prevailing theory — that the disease traveled through foul air, the so-called miasma. Instead, he walked the neighborhood with a notebook, marking deaths on a map. The cluster that emerged pointed, with uncomfortable precision, at a water pump on Broad Street.
Snow had not discovered a statistical correlation. He had identified a cause.
The distinction matters enormously. Thousands of people lived near the pump and did not die. Dozens died who lived farther away but happened to work near it. The pattern alone did not tell the story. Snow had to reason about mechanisms — about how cholera spread, about which water was shared and which was not, about what would happen if someone intervened and removed the pump handle.
That last word, intervene, turns out to be the key to everything in this book.
0.2 Three Ways to Reason Under Uncertainty
Modern quantitative reasoning comes in roughly three flavors, and they answer subtly different questions.
The first is frequentist statistics. A frequentist asks: given that this hypothesis is true, how often would I see data like this? It is a powerful framework, responsible for much of the scientific infrastructure of the twentieth century. But it has a notable quirk: it cannot directly tell you how probable a hypothesis is. It can only tell you how improbable the data would be if the hypothesis were false.
The second is Bayesian reasoning. A Bayesian asks: given this data, how should I update my beliefs? This is closer to how humans actually think. You begin with some prior expectation — cholera probably travels in water, because of what you know about other waterborne pathogens — and you revise it as evidence accumulates. The mathematics is straightforward, but the philosophical implications have been argued about for two centuries and show no signs of settling down.
The third is causal inference. A causal reasoner asks: what would happen if I changed something? Not what pattern do I see, but what would the world look like under a different intervention? This framework, formalized largely in the last forty years, is arguably the most powerful of the three — and the least widely understood.
This book covers all three, and more. But the thread connecting them is a single idea: how do you reason well when you don’t know everything?
0.3 A Map of the Book
Part I builds the foundation. Probability is not just arithmetic — it is a way of encoding belief, and Bayesian inference is the machinery that keeps those beliefs honest as evidence arrives. These two chapters are the bedrock on which everything else rests.
Part II takes up causality directly. Why does correlation mislead us so reliably? What is a cause, precisely, and how can you identify one without running a controlled experiment? The tools here — directed graphs, the do-calculus, counterfactual reasoning — were developed by researchers who were frustrated that statistics could describe the world but not explain it.
Part III explores what happens when the world refuses to be crisp. Classical logic deals in true and false. Fuzzy logic deals in somewhat true and more or less false, which turns out to be a much better description of how categories actually work — in both language and in the brain.
Part IV surveys the landscape of learning algorithms. Starting from linear regression and working through neural networks, deep learning, and causal machine learning, this section asks a practical question: what are these systems actually doing, and what are the limits of what they can learn?
Part V turns the lens on human cognition. The Bayesian brain hypothesis. The way people reason about causes and interventions. The fuzzy, prototype-based way that concepts seem to be stored. And finally, the uncomfortable question: what can machines learn that humans cannot, and vice versa?
Code
import numpy as npimport matplotlib.pyplot as plt# Prior: we believe the coin is fair (Beta(1,1) = uniform)# We flip 10 times and see 7 heads. How should our belief update?from scipy.stats import betatheta = np.linspace(0, 1, 300)prior = beta.pdf(theta, 1, 1) # flat priorposterior_5h = beta.pdf(theta, 6, 2) # 5 heads, 1 tails (Beta(1+5, 1+1))posterior_7h = beta.pdf(theta, 8, 3) # 7 heads, 3 tails (Beta(1+7, 1+3))fig, ax = plt.subplots(figsize=(8, 4))ax.plot(theta, prior, label="Prior (no data)", linestyle="--", color="gray")ax.plot(theta, posterior_5h, label="After 5 heads in 6 flips", color="#4e79a7")ax.plot(theta, posterior_7h, label="After 7 heads in 10 flips", color="#f28e2b")ax.set_xlabel("θ (probability of heads)")ax.set_ylabel("Probability density")ax.set_title("Bayesian belief update — coin bias")ax.legend()plt.tight_layout()plt.show()
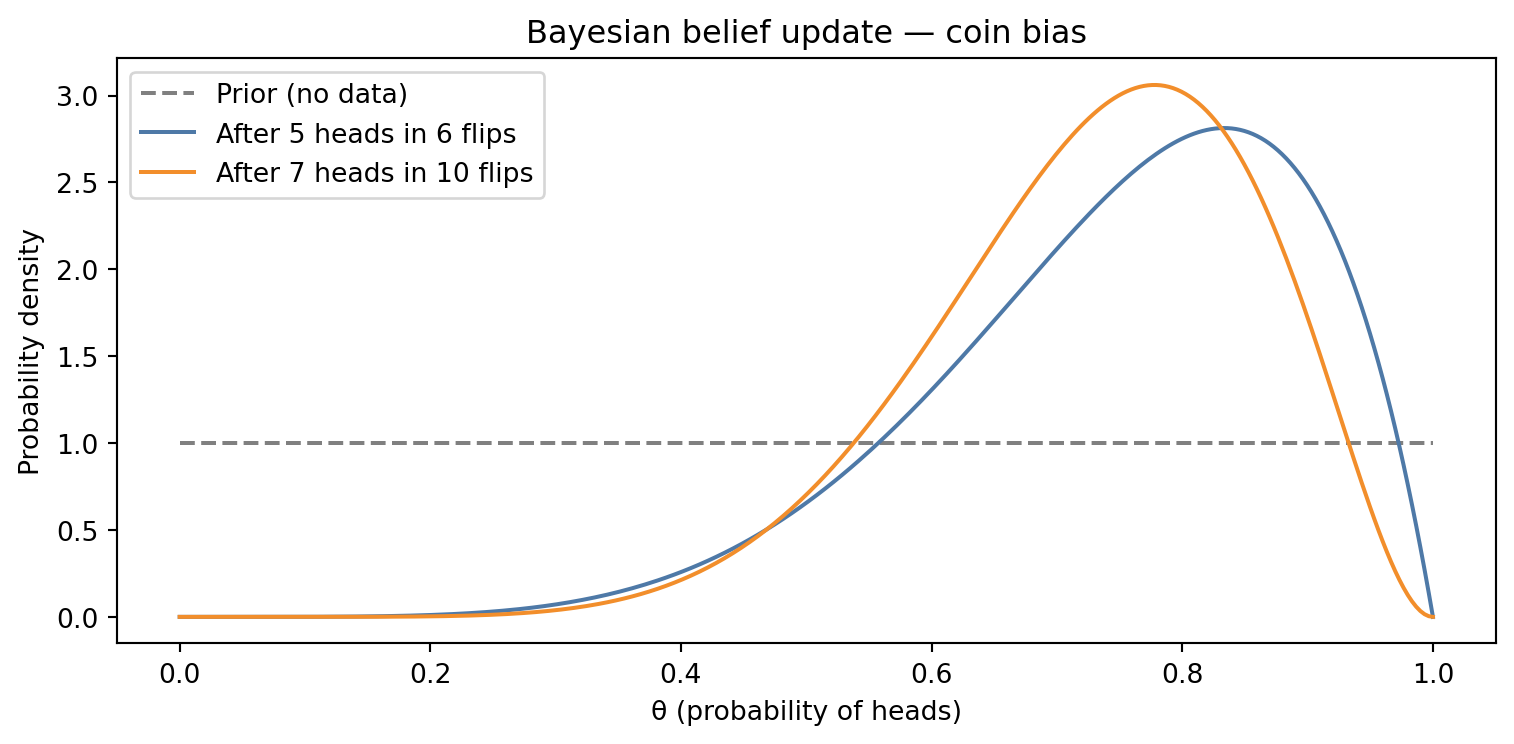
Figure 1: A coin flip and a belief update — the simplest possible Bayesian story.
The figure above shows the simplest possible Bayesian story: we begin with no opinion about whether a coin is fair, watch it land heads seven times in ten flips, and update our beliefs accordingly. The posterior distribution — our revised opinion after seeing data — has shifted toward higher values of θ. It has not moved to certainty that the coin is biased, because ten flips is not a lot of evidence. It has moved proportionally to the evidence, which is exactly what we would hope rational reasoning to do.
That proportionality is what this book is about.
0.4 Summary
Learning, in the broadest sense, is the process of updating beliefs in response to evidence.
Frequentist statistics, Bayesian reasoning, and causal inference are three complementary frameworks, each suited to different questions.
The key question that separates causal reasoning from statistical reasoning is: what would happen if we intervened?
The five parts of this book follow a connected arc from probability and belief, through causality and fuzzy logic, through learning algorithms, to the architecture of human cognition.
0.5 Further Reading
Pearl and Mackenzie (2018) provides an accessible entry into causal reasoning, written for a general audience — an excellent companion to Part II of this book. Jaynes (2003) is the foundational text on probability as logic; dense, but enormously rewarding. For the history of statistical thinking, Salsburg’s The Lady Tasting Tea is a pleasure.
Jaynes, Edwin T. 2003. Probability Theory: The Logic of Science. Cambridge University Press.
Pearl, Judea, and Dana Mackenzie. 2018. The Book of Why: The New Science of Cause and Effect. Basic Books.
Source Code
---title: "Introduction: The Problem of Learning"---::: {.callout-note icon=false}## Learning Objectives- Understand what we mean by *learning* in both human and machine contexts- Distinguish between the three major frameworks for reasoning under uncertainty- Appreciate why causal thinking is fundamentally different from statistical pattern-matching- Get a map of the book's five-part journey:::## The Oracle ProblemIn the summer of 1854, a physician named John Snow did something that was, at the time, considered deeply strange. There was a cholera epidemic tearing through the Soho district of London, and Snow did not reach for the prevailing theory — that the disease traveled through foul air, the so-called *miasma*. Instead, he walked the neighborhood with a notebook, marking deaths on a map. The cluster that emerged pointed, with uncomfortable precision, at a water pump on Broad Street.Snow had not discovered a statistical correlation. He had identified a cause.The distinction matters enormously. Thousands of people lived near the pump and did not die. Dozens died who lived farther away but happened to work near it. The pattern alone did not tell the story. Snow had to reason about mechanisms — about how cholera spread, about which water was shared and which was not, about what would happen if someone *intervened* and removed the pump handle.That last word, *intervene*, turns out to be the key to everything in this book.## Three Ways to Reason Under UncertaintyModern quantitative reasoning comes in roughly three flavors, and they answer subtly different questions.The first is **frequentist statistics**. A frequentist asks: given that this hypothesis is true, how often would I see data like this? It is a powerful framework, responsible for much of the scientific infrastructure of the twentieth century. But it has a notable quirk: it cannot directly tell you how probable a hypothesis is. It can only tell you how improbable the data would be if the hypothesis were false.The second is **Bayesian reasoning**. A Bayesian asks: given this data, how should I update my beliefs? This is closer to how humans actually think. You begin with some prior expectation — cholera probably travels in water, because of what you know about other waterborne pathogens — and you revise it as evidence accumulates. The mathematics is straightforward, but the philosophical implications have been argued about for two centuries and show no signs of settling down.The third is **causal inference**. A causal reasoner asks: what would happen if I changed something? Not *what pattern do I see*, but *what would the world look like under a different intervention*? This framework, formalized largely in the last forty years, is arguably the most powerful of the three — and the least widely understood.This book covers all three, and more. But the thread connecting them is a single idea: *how do you reason well when you don't know everything?*## A Map of the Book**Part I** builds the foundation. Probability is not just arithmetic — it is a way of encoding belief, and Bayesian inference is the machinery that keeps those beliefs honest as evidence arrives. These two chapters are the bedrock on which everything else rests.**Part II** takes up causality directly. Why does correlation mislead us so reliably? What is a cause, precisely, and how can you identify one without running a controlled experiment? The tools here — directed graphs, the do-calculus, counterfactual reasoning — were developed by researchers who were frustrated that statistics could describe the world but not explain it.**Part III** explores what happens when the world refuses to be crisp. Classical logic deals in true and false. Fuzzy logic deals in *somewhat true* and *more or less false*, which turns out to be a much better description of how categories actually work — in both language and in the brain.**Part IV** surveys the landscape of learning algorithms. Starting from linear regression and working through neural networks, deep learning, and causal machine learning, this section asks a practical question: what are these systems actually doing, and what are the limits of what they can learn?**Part V** turns the lens on human cognition. The Bayesian brain hypothesis. The way people reason about causes and interventions. The fuzzy, prototype-based way that concepts seem to be stored. And finally, the uncomfortable question: what can machines learn that humans cannot, and vice versa?```{python}#| label: fig-intro-demo#| fig-cap: "A coin flip and a belief update — the simplest possible Bayesian story."import numpy as npimport matplotlib.pyplot as plt# Prior: we believe the coin is fair (Beta(1,1) = uniform)# We flip 10 times and see 7 heads. How should our belief update?from scipy.stats import betatheta = np.linspace(0, 1, 300)prior = beta.pdf(theta, 1, 1) # flat priorposterior_5h = beta.pdf(theta, 6, 2) # 5 heads, 1 tails (Beta(1+5, 1+1))posterior_7h = beta.pdf(theta, 8, 3) # 7 heads, 3 tails (Beta(1+7, 1+3))fig, ax = plt.subplots(figsize=(8, 4))ax.plot(theta, prior, label="Prior (no data)", linestyle="--", color="gray")ax.plot(theta, posterior_5h, label="After 5 heads in 6 flips", color="#4e79a7")ax.plot(theta, posterior_7h, label="After 7 heads in 10 flips", color="#f28e2b")ax.set_xlabel("θ (probability of heads)")ax.set_ylabel("Probability density")ax.set_title("Bayesian belief update — coin bias")ax.legend()plt.tight_layout()plt.show()```The figure above shows the simplest possible Bayesian story: we begin with no opinion about whether a coin is fair, watch it land heads seven times in ten flips, and update our beliefs accordingly. The posterior distribution — our revised opinion after seeing data — has shifted toward higher values of θ. It has not moved to *certainty* that the coin is biased, because ten flips is not a lot of evidence. It has moved *proportionally* to the evidence, which is exactly what we would hope rational reasoning to do.That proportionality is what this book is about.## Summary- Learning, in the broadest sense, is the process of updating beliefs in response to evidence.- Frequentist statistics, Bayesian reasoning, and causal inference are three complementary frameworks, each suited to different questions.- The key question that separates causal reasoning from statistical reasoning is: *what would happen if we intervened?*- The five parts of this book follow a connected arc from probability and belief, through causality and fuzzy logic, through learning algorithms, to the architecture of human cognition.## Further Reading@pearl2018book provides an accessible entry into causal reasoning, written for a general audience — an excellent companion to Part II of this book. @jaynes2003probability is the foundational text on probability as logic; dense, but enormously rewarding. For the history of statistical thinking, Salsburg's *The Lady Tasting Tea* is a pleasure.