Implement and visualize a small network learning hierarchical representations
12.1 What Depth Buys You
A neural network with one hidden layer can approximate any continuous function. So why do we need deep networks — networks with many layers?
The answer is efficiency. A shallow network may need exponentially many units to represent a function that a deep network can represent with polynomially many. More importantly, depth enables hierarchical representation learning: each layer transforms its inputs into increasingly abstract features.
This is visible in convolutional networks trained on images. The first layer learns to detect edges and color gradients. The second layer combines edges into shapes. The third layer combines shapes into object parts. The final layers combine parts into objects. At no point was this hierarchy specified by the designer — it emerged from learning.
This spontaneous organization mirrors what we know about the visual cortex: it too processes visual information in a hierarchy of increasing abstraction, from V1 (edges) to higher areas (faces, scenes).
12.2 Convolutional Networks
Convolutional Neural Networks (CNNs) exploit a simple structure in visual data: nearby pixels are more informative about each other than distant pixels, and useful features look similar no matter where they appear in the image.
A convolutional layer learns small filters — typically 3×3 or 5×5 patches — that are slid across the entire input. Each filter detects a particular local pattern. Because the same filter is applied everywhere (weight sharing), the network learns translation-invariant features without needing separate weights for each image location.
Pooling layers downsample the feature maps, progressively reducing spatial resolution while increasing the number of abstract feature channels.
12.3 Attention and Transformers
The architectural innovation that transformed natural language processing — and subsequently much of the rest of deep learning — was the attention mechanism (Vaswani et al., 2017). Rather than processing sequences step by step, attention allows every element in a sequence to directly interact with every other element, with interaction strength learned from the data.
A transformer is a network built entirely from attention layers. It has no recurrence, no convolution. It processes the entire sequence in parallel. The result was a dramatic improvement in performance on language tasks, and then on image recognition, protein structure prediction, and much else.
12.4 Representation Learning and Transfer
One of the most practically significant properties of deep networks is that the representations learned for one task transfer to others. A network trained on ImageNet (1.4 million labeled images) learns representations of shapes, textures, and objects that are useful for almost any visual task — even tasks quite different from the original.
This is transfer learning. It means that organizations without access to massive labeled datasets can still benefit from deep learning by fine-tuning a pre-trained network on their specific problem.
Code
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.neural_network import MLPClassifierfrom sklearn.datasets import make_moonsX, y = make_moons(n_samples=300, noise=0.2, random_state=42)clf = MLPClassifier(hidden_layer_sizes=(8,), activation='relu', max_iter=1000, random_state=0)clf.fit(X, y)# Hidden layer activations (first layer output before final classification)hidden_activations = np.maximum(0, X @ clf.coefs_[0] + clf.intercepts_[0])fig, axes = plt.subplots(1, 2, figsize=(12, 4))axes[0].scatter(X[:, 0], X[:, 1], c=y, cmap='RdBu', edgecolors='k', s=20, alpha=0.7)axes[0].set_title("Input space (not linearly separable)")axes[0].set_xlabel("x₁"); axes[0].set_ylabel("x₂")axes[1].scatter(hidden_activations[:, 0], hidden_activations[:, 1], c=y, cmap='RdBu', edgecolors='k', s=20, alpha=0.7)axes[1].set_title("Learned representation (hidden layer)")axes[1].set_xlabel("h₁"); axes[1].set_ylabel("h₂")plt.suptitle("Representation learning: from tangled to separable", y=1.02)plt.tight_layout()plt.show()
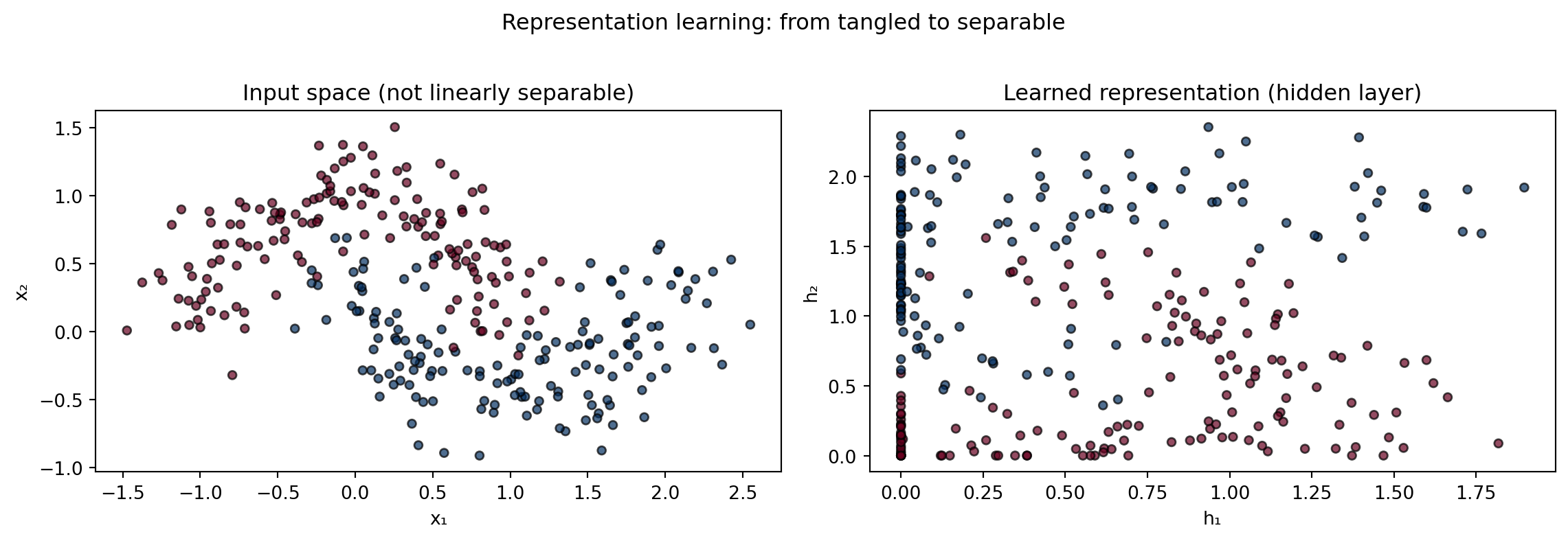
Figure 12.1: A two-layer network learns to separate a non-linearly separable dataset. Plotting the hidden-layer activations reveals the learned representation.
12.5 Summary
Depth enables hierarchical feature learning: each layer builds increasingly abstract representations on top of the previous layer’s output.
Convolutional networks exploit spatial locality and translation invariance for visual data; weight sharing dramatically reduces the number of parameters.
The attention mechanism allows direct interaction between all elements of a sequence; transformers are built from attention layers and have become the dominant architecture in language modeling.
Transfer learning exploits the generality of learned representations: networks pre-trained on large datasets can be fine-tuned for specific tasks at much lower cost.
12.6 Further Reading
Goodfellow et al. (2016) covers CNNs in Chapter 9 and sequence models in Chapter 10. The original transformer paper, Vaswani et al. (2017), Attention Is All You Need, is short and readable. For a conceptual treatment of representation learning, Bengio et al. (2013), Representation Learning: A Review and New Perspectives is the standard survey.
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. MIT Press.
Source Code
---title: "Deep Learning and Representation"---::: {.callout-note icon=false}## Learning Objectives- Understand why depth — more layers — enables qualitatively different kinds of learning- Describe the role of feature learning in modern deep networks- Explain key architectural ideas: convolutional layers, attention, residual connections- Implement and visualize a small network learning hierarchical representations:::## What Depth Buys YouA neural network with one hidden layer can approximate any continuous function. So why do we need deep networks — networks with many layers?The answer is efficiency. A shallow network may need exponentially many units to represent a function that a deep network can represent with polynomially many. More importantly, depth enables *hierarchical representation learning*: each layer transforms its inputs into increasingly abstract features.This is visible in convolutional networks trained on images. The first layer learns to detect edges and color gradients. The second layer combines edges into shapes. The third layer combines shapes into object parts. The final layers combine parts into objects. At no point was this hierarchy specified by the designer — it emerged from learning.This spontaneous organization mirrors what we know about the visual cortex: it too processes visual information in a hierarchy of increasing abstraction, from V1 (edges) to higher areas (faces, scenes).## Convolutional NetworksConvolutional Neural Networks (CNNs) exploit a simple structure in visual data: nearby pixels are more informative about each other than distant pixels, and useful features look similar no matter where they appear in the image.A convolutional layer learns small *filters* — typically 3×3 or 5×5 patches — that are slid across the entire input. Each filter detects a particular local pattern. Because the same filter is applied everywhere (weight sharing), the network learns translation-invariant features without needing separate weights for each image location.Pooling layers downsample the feature maps, progressively reducing spatial resolution while increasing the number of abstract feature channels.## Attention and TransformersThe architectural innovation that transformed natural language processing — and subsequently much of the rest of deep learning — was the **attention mechanism** (Vaswani et al., 2017). Rather than processing sequences step by step, attention allows every element in a sequence to directly interact with every other element, with interaction strength learned from the data.A transformer is a network built entirely from attention layers. It has no recurrence, no convolution. It processes the entire sequence in parallel. The result was a dramatic improvement in performance on language tasks, and then on image recognition, protein structure prediction, and much else.## Representation Learning and TransferOne of the most practically significant properties of deep networks is that the representations learned for one task transfer to others. A network trained on ImageNet (1.4 million labeled images) learns representations of shapes, textures, and objects that are useful for almost any visual task — even tasks quite different from the original.This is *transfer learning*. It means that organizations without access to massive labeled datasets can still benefit from deep learning by fine-tuning a pre-trained network on their specific problem.```{python}#| label: fig-representation-learning#| fig-cap: "A two-layer network learns to separate a non-linearly separable dataset. Plotting the hidden-layer activations reveals the learned representation."import numpy as npimport matplotlib.pyplot as pltfrom sklearn.neural_network import MLPClassifierfrom sklearn.datasets import make_moonsX, y = make_moons(n_samples=300, noise=0.2, random_state=42)clf = MLPClassifier(hidden_layer_sizes=(8,), activation='relu', max_iter=1000, random_state=0)clf.fit(X, y)# Hidden layer activations (first layer output before final classification)hidden_activations = np.maximum(0, X @ clf.coefs_[0] + clf.intercepts_[0])fig, axes = plt.subplots(1, 2, figsize=(12, 4))axes[0].scatter(X[:, 0], X[:, 1], c=y, cmap='RdBu', edgecolors='k', s=20, alpha=0.7)axes[0].set_title("Input space (not linearly separable)")axes[0].set_xlabel("x₁"); axes[0].set_ylabel("x₂")axes[1].scatter(hidden_activations[:, 0], hidden_activations[:, 1], c=y, cmap='RdBu', edgecolors='k', s=20, alpha=0.7)axes[1].set_title("Learned representation (hidden layer)")axes[1].set_xlabel("h₁"); axes[1].set_ylabel("h₂")plt.suptitle("Representation learning: from tangled to separable", y=1.02)plt.tight_layout()plt.show()```## Summary- Depth enables hierarchical feature learning: each layer builds increasingly abstract representations on top of the previous layer's output.- Convolutional networks exploit spatial locality and translation invariance for visual data; weight sharing dramatically reduces the number of parameters.- The attention mechanism allows direct interaction between all elements of a sequence; transformers are built from attention layers and have become the dominant architecture in language modeling.- Transfer learning exploits the generality of learned representations: networks pre-trained on large datasets can be fine-tuned for specific tasks at much lower cost.## Further Reading@goodfellow2016deep covers CNNs in Chapter 9 and sequence models in Chapter 10. The original transformer paper, Vaswani et al. (2017), *Attention Is All You Need*, is short and readable. For a conceptual treatment of representation learning, Bengio et al. (2013), *Representation Learning: A Review and New Perspectives* is the standard survey.